
一、即使我们已使用OpenSpec、Superpowers,为什么还是需要事先专门优化规约文档?
假设这么一条需求,你可能在很多项目里都见过:
活动期间给用户发放优惠券,用户可以在结算时使用。
乍一看没什么问题,对吧?人类读者能"意会"个大概。但把它直接丢进 OpenSpec 的流程,事情就开始跑偏了:
- 给所有用户都发了券,含黑名单用户;
- 没设置每人上限,同一个用户刷了几千张;
- 没做有效期和叠加规则,优惠券可以无限叠加,结算金额算出来是负数。
这不是 AI 的错。是我给的原材料太糙了。
⚠️核心观点:
并不是说,让你必须在"低精度的规约文档"中就必须写清楚所有的细节,而是利用AI海量的训练数据,从AI替你做决定去实施,变成AI帮你判断并提供方案,让你去决定。
在把这份"低精度的规约文档"交给任何AI框架之前(OpenSpec、Superpowers、GSD等等),花半小时做一次深度优化,远比事后花半天时间修 bug 划算。
下面我们来探讨几个关键概念。
自然语言天然歧义
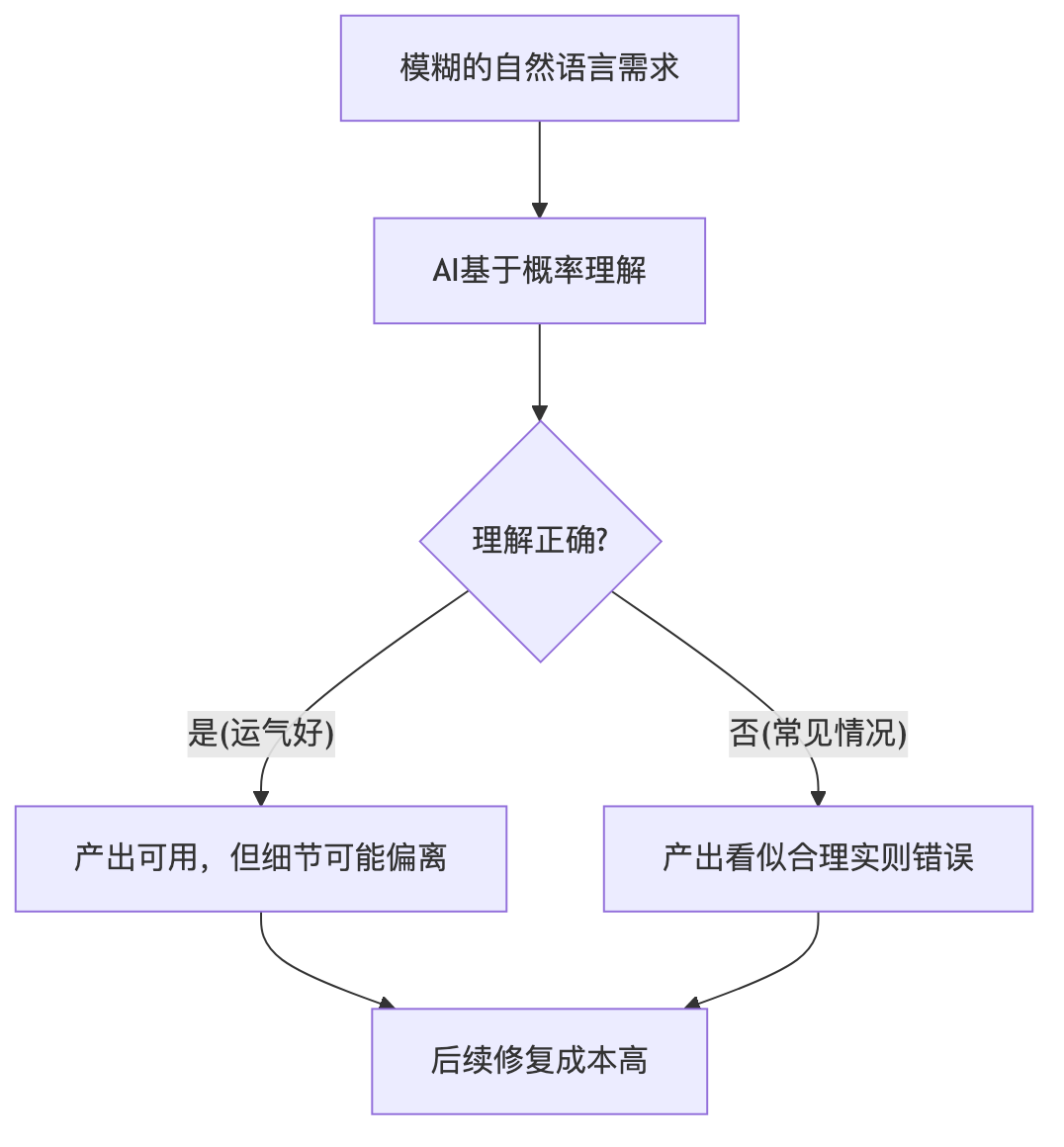
人与人沟通之所以高效,恰恰不是因为语言精确,而是因为我们有大量共享的背景知识。你说"帮我把门关上",对方默认你知道是哪扇门、什么时候关、关到什么程度。我们不需要把这些说全。
但 AI 没有这些默认共识。AI 不像人能通过上下文"揣摩"你的真实意图,它只能按概率选择最可能的解释。而这个"最可能"的解释,未必是你想要的。
在这个过程中,自然语言的歧义可能带来重大误解。更多的内容请参考我的另一篇文章 意图对齐:AI 编程时代被忽视的核心工程能力,其中详细讨论了自然语言处理中的一些潜在问题。
- “支持批量导入” —— 一次能导入多少条?10条?10万条?
- “数据实时更新” —— 毫秒级?秒级?还是每分钟刷新一次?
- “提高性能” —— 现在的性能基线是什么?提高到多少算"提高"了?
这些问题在人类沟通中通常能通过后续对话补充,但如果规约文档本身就带着这些缺口直接进入 AI 驱动的开发流程,缺口就会被 AI 用"合理的假设"填上。而这些假设,大概率不是你想要的。
OpenSpec 提问机制的不足
我得承认,OpenSpec 和 Superpowers 这类规约驱动框架的思路是对的:拿不准就提问,不要自作主张。它们的提问机制也确实能帮我们补全一些遗漏的需求。
但实际用下来,我的感受是它们的澄清力度远远不够。
我的体会
OpenSpec 或 Superpowers 的提问机制,有基本的追问意识,但深度和广度都不够,需要有人先把需求理清楚,它才能在这个基础上问出有价值的问题。否则,它连自己不知道该问什么都意识不到。
第一个问题:提问数量偏少。一个稍复杂的工程任务(比如"构建一个带权限管理的订单系统"),真正需要追问的细节少则二三十个,多则上百个。但 OpenSpec 通常只会提三五个问题就觉得自己"理解了"。它不会追着问:订单金额超过多少需要特殊审批?权限被撤销后正在处理的订单怎么处理?
第二个问题:AI 的理解带有随机性。同一个模糊的需求描述,同一个提问,在不同时刻得到的理解和回答可能就不一样。甚至同一个问题,第一次他询问我了,第二次却什么也不问,自作主张决定了。
第三个问题:提问的粒度太粗。比如字段校验规则、异常分支处理、接口超时策略 —— 它一个都没问。因为这些细节太细了,它从模糊的原始文档里根本识别不出这些漏洞。
细粒度掌控必须前置
有时候,我们对一个项目的实施细节有明确的掌控要求。不是"大概做出来就行",而是"这里必须这样实现,那里绝对不能那样处理"。
掌控感来源于确定性
当你在文档阶段就把细节钉死,AI 的执行路径就变窄了。路径越窄,偏离目标的可能性就越小。
举个例子。一个支付模块的实现方案,如果你只告诉 AI"支持多种主流支付方式",它可能会自行决定:
- 同步还是异步回调
- 超时时间多长
- 失败后重试几次
- 重试失败后怎么处理
- 是否引入防重放攻击机制
这些决策本身没错,但你很可能已经对其中每一项都有明确要求。如果规约文档不提前写清楚,等 AI 生成完方案再一个个去纠正,工作量反而翻倍了。
我的做法是:在进入 OpenSpec 或 Superpowers 流程之前,先用一套系统化的规则,把规约文档的每个模糊点都打磨到足够精确,就像本文开始时,我的核心观点:"并不是说,让你必须在"低精度的规约文档"中就必须写清楚所有的细节,而是利用AI海量的训练数据,从AI替你做决定去实施,变成AI帮你判断并提供方案,让你去决定"。这样做的好处是:
- 减少 AI 的决策空间:细节越明确,AI 自行假设的机会越少
- 降低返工风险:方向在文档阶段就对齐了,代码产出不会偏离太远
- 提高审查效率:规约驱动产出的方案文档,质量本身也会更高,审查成本更小
二、我是如何对一个低精度的规约文档进行优化的?
核心优化规则
a. 歧义词检测与替换
这是优化的第一道关卡。自然语言天然存在大量表意模糊的词汇,如果不加甄别直接使用,会导致AI或开发者产生多种理解路径。
“和"的歧义:原文说"系统需要支持A和B功能”,这里的"和"可能是并列关系(两个功能都需要),也可能是列举关系(举例说明)。改进方案:如果是并列需求,改为"系统必须同时支持A功能与B功能";如果是举例,改为"系统需要支持A、B等功能"。
“或"的歧义:原文"用户可以微信或支付宝登录”,这里的"或"是"二选一"还是"至少选一个都行"?如果原意是用户只能选择其中一种方式,应改为"用户只能在微信和支付宝中选择一种方式登录";如果原意是两种方式都支持但不强求同时使用,应改为"用户可使用微信登录,也可使用支付宝登录,至少支持其中一种"。
“如果"遗漏"否则”:原文"如果用户连续输错密码3次则锁定账号",但没说如果没输错3次怎么办、锁定后如何解锁。改进方案必须补充完整条件分支:“如果用户连续输错密码3次则锁定账号30分钟;否则正常进入系统;锁定期满后自动解除,用户可重新尝试。”
语气词模糊:“应该"和"尽量"是最容易被忽略的约束。“系统应该记录日志"和"系统必须记录日志”,前者给执行者留了"不记录也不违规"的借口,后者才是强制要求。改进时统一替换:强制场景用"必须”,建议场景用"优先",彻底消灭"应该/尽量"。
数量与时间模糊:“一些数据"“很多用户"“尽快完成"“响应要快”——这类表达在执行层面没有任何可操作性。必须转化为具体的数值、范围或时间指标。
b. 逻辑完整性检查
一条完整的指令必须覆盖所有可能的执行路径,不能只描述一种路径。
成功与失败双向覆盖:原文"用户提交订单后保存数据”,只说了成功流程。完整描述应为:“用户提交订单后,系统将数据保存到数据库;保存成功则返回订单号和成功提示;保存失败则返回具体错误原因,提示用户稍后重试,同时记录错误日志供排查。”
正常流程与异常处理:原文"上传文件后解析内容”,但文件超过大小限制怎么办?文件格式不支持怎么办?上传中断怎么办?完整描述必须包含:文件类型校验、大小限制、超时处理、网络中断重试机制、解析失败的用户反馈。
能做与不能做:原文"管理员可以操作”,没说哪些管理员、哪些操作、哪些情况不能操作。必须明确权限边界:哪些角色被排除在外?哪些操作被禁止?例如:“超级管理员可以删除任何文章;普通管理员只能删除自己发布的文章;所有管理员都不能删除已归档的文章。”
默认行为定义:当所有条件都不满足时,系统应该如何行动?原文必须明确定义:“如果用户的角色不在上述列表中,默认仅拥有查看权限,无法进行编辑或删除操作。”
c. 优先级与顺序明确
当多个任务或规则并存时,如果不明确执行顺序和优先级,会导致执行混乱。
顺序编号:原文说"先做A,再做B,顺便做C",“顺便"二字完全破坏了优先级。改进后:“第一步:执行A操作 → 第二步:执行B操作 → 第三步:执行C操作。”
优先级标签:使用【必须】、【重要】、【可选】三级标签强制区分约束强度。例如:
- 【必须】用户密码长度不少于8位
- 【重要】密码应包含大小写字母和数字
- 【可选】建议定期更换密码(每90天)
判断标准具体化:原文说"重要的事情先处理”,但"重要"是主观判断。必须给出客观标准:“当订单金额超过1万元或客户等级为VIP时,视为高优先级订单,必须在2小时处理;其他订单按提交时间顺序处理。”
d. 数量与时间精确化
模糊的数量和时间表达是需求失真的主要原因。
数量精确化对照表:
- “一些数据” → “不超过100条数据”
- “很多用户” → “同时在线用户超过1000人时”
- “金额很大” → “单笔金额超过10万元”
- “少数情况” → “发生率低于5%的场景”
时间精确化对照表:
- “尽快完成” → “在24小时内完成”
- “响应要快” → “首屏加载时间不超过3秒”
- “经常发生” → “每周至少发生3次”
- “一段时间后” → “延迟500毫秒后”
- “实时更新” → “数据刷新间隔不超过30秒”
e. 角色与权限明确
权限描述模糊是安全事故的根源。
角色类型明确化:原文"用户可以查看",必须细化为:“普通用户仅可查看自己创建的订单;付费用户可查看所有公开订单;超级管理员可查看所有订单(包含已删除的)。”
操作权限明确化:原文"有权限的用户可以编辑文章",必须列出具体清单:
- 包含:修改文章标题、修改正文内容、添加或删除图片、更改分类和标签
- 不包含:删除文章(仅管理员可执行)、发布文章(需审核员审批)、修改作者信息(仅作者本人可修改)
权限触发条件:明确何时获得、何时失去权限。“用户完成实名认证后自动获得编辑权限;账号被封禁期间所有编辑权限立即冻结。”
实施准则
- 不猜需求:有歧义先问澄清,不假设隐含需求,不按"常见做法"擅自添加未要求的功能
- 保持简单:50行能解决不写200行,不过度抽象,不创建不必要的抽象层/接口/工厂模式,优先使用现成方案
- 只做局部修改:严格限定修改范围,不顺手重构其他文件,不统一命名风格,改动最小化
- 先定义"做成了":修bug先复现,加功能先定义验收标准和测试方式,完成后必须运行验证,有可验证证据
- 分步实施,控制上下文:大任务拆小步骤逐步完成,控制上下文不超过60%,过长主动建议新会话,避免AI记忆混乱和幻觉
- 注释和提交:代码必须编写注释
- 分阶段Git提交:每个逻辑单元完成后立即提交,格式:前缀: 描述。前缀规范:feat:新功能、fix:bug修复、refactor:重构、docs:文档、style:格式、test:测试、chore:构建配置
- Golang项目结构:新项目按标准layout(cmd/internal/pkg/api/configs/scripts/docs),旧项目保持现有结构一致性,不擅自规范化
- 防御式编程(软件任务必须):
- 参数校验:所有外部输入入口必校验
- 空值处理:对可能为nil的值必检查
- 错误处理:每个可能失败的操作必须有明确错误处理路径
- 边界条件:数组索引、字符串长度、数值范围必保护
- 默认值:配置项和可选参数提供合理默认值
- 失败安全:部分组件失败时降级运行,不完全崩溃
- 日志记录:关键操作和异常路径必记录
实施流程
Step 1:询问背景知识
- 先确认是否有可供调查的背景资料(项目代码、文档、知识库)
- 有背景知识则读取相关文件,理解项目/业务上下文,基于实际细节精准提问
Step 2:判断是否加入TDD(软件开发类任务)
- 涉及编程/代码实现/API开发时,询问是否加入测试驱动开发要求
- 加入后提问补充测试类型、覆盖范围、边界条件等问题
Step 3:选择提问方式
- 极简模式:1轮提问,每轮1-5个问题,适合问题明确/时间紧迫
- 普通模式(推荐):1-3轮提问,每轮3-5个问题,平衡效率与深度
- 专业模式:3-5轮提问,每轮5-10个问题,深入全面覆盖细节
Step 4:分析原文并多轮提问澄清
- 识别歧义词汇、模糊表达、缺失条件、隐含假设
- 提问简洁精准,选项清晰易懂,标注推荐项,提供自定义回答
- 每一轮足够清晰即可提前结束
Step 5:输出优化方案
- 在原文件同目录创建
原文件名_优化版.md - 自动结构化重新排版,不添加额外信息(评分/总结/版本等)
- 纯净文档输出,可直接使用
三、最后
把规约文档优化做在前面这件事,我第一次系统性地实践,效果比我预期的要好得多。
回顾一下全文的核心观点:
第一,别指望 OpenSpec 或 Superpowers 能替你补全需求质量。 它们的提问机制是"锦上添花",不是"雪中送炭"。在模糊的原文基础上提问,得到的答案也注定是模糊的。
第二,歧义不是小事。 自然语言里的每一个模糊词,在 AI 眼中都是一个可自由发挥的空间。“自动"“支持"“快速"这些词在人类沟通里无伤大雅,但在规约文档里就是埋雷。
第三,优化不是重写。 你不需要把文档从三四行扩写成三四千字。关键是消除歧义、补全分支、钉死边界和数量。很多时候就是在关键地方加一个"必须”,把一个模糊词换成具体数值,文档的质量就上一个台阶。
第四,把它工具化。 整套规则写成一个 Skill,让它自动跑起来。一次配置,反复使用,这才是工程思维。
第五,搭建一套自我进化的 LLM-Wiki。 这套优化规则不是一次性消耗品——每次踩过的坑、新发现的歧义模式、总结出来的校验清单,都应该沉淀到你的个人知识库里。我在 学习 Karpathy 的 LLM-Wiki 方法论之后的自我实践 里详细写过这套方法论:把 AI 会话中的碎片经验提炼成结构化知识,再通过 wikilink 互连形成知识图谱。规约优化规则只是其中的一个节点,随着你持续使用,它会越长越厚实,最终成为你自己的"工程资产库”。
如果你还没有做过类似的事情,我建议从今天开始就尝试。拿一份你最近写的需求文档,按照第二部分里的规则逐项过一遍。你会惊讶地发现,那些以为"已经很清楚了"的地方,其实处处是坑。