
一、即使我們已使用 OpenSpec、Superpowers,為什麼還是需要事先專門優化規格文件?
假設這麼一條需求,你可能在很多專案裡都見過:
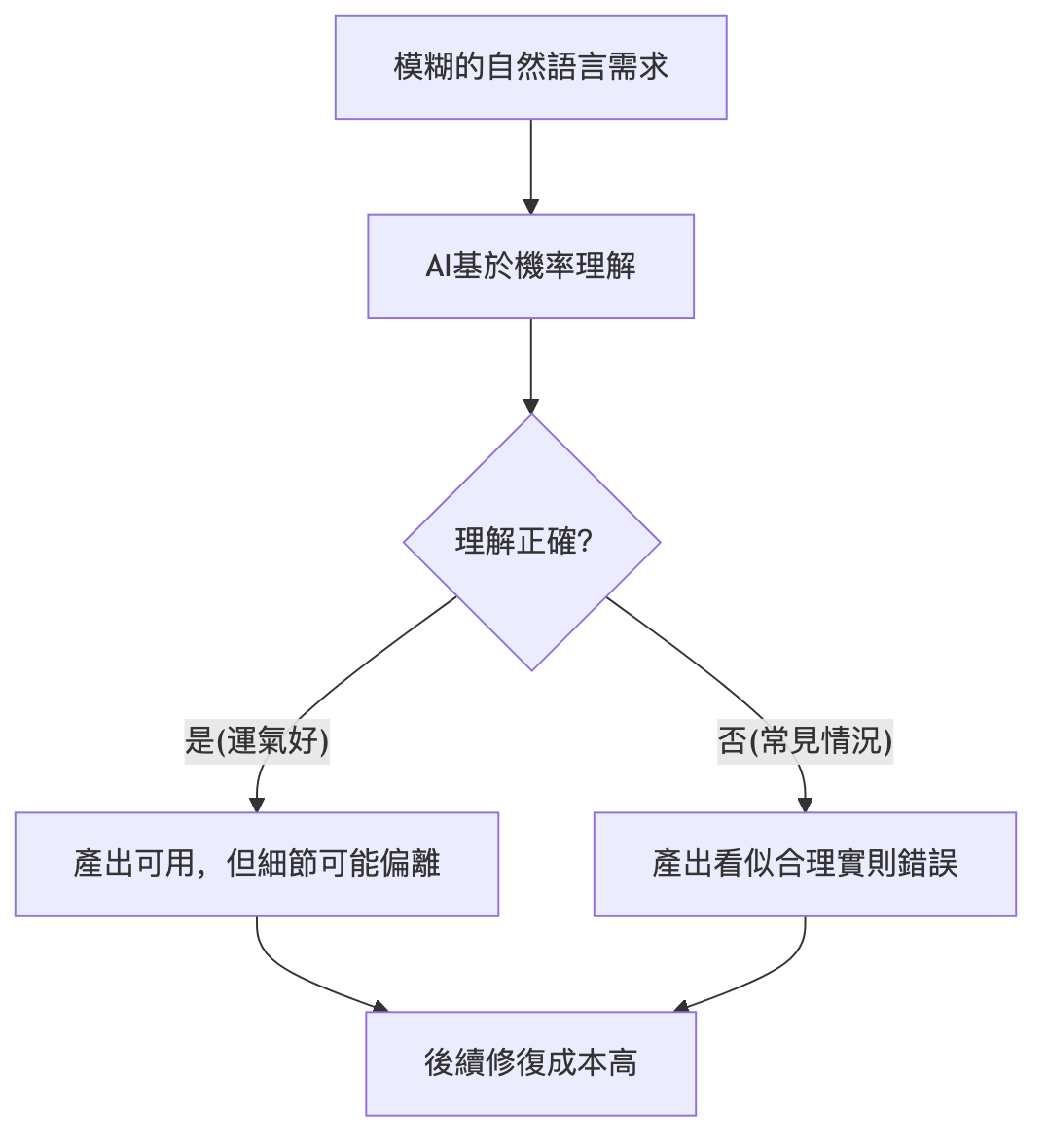
活動期間給使用者發放優惠券,使用者可以在結算時使用。
乍一看沒什麼問題,對吧?人類讀者能"意會"個大概。但把它直接丟進 OpenSpec 的流程,事情就開始跑偏了:
- 給所有使用者都發了券,含黑名單使用者;
- 沒設定每人上限,同一個使用者刷了好幾千張;
- 沒做有效期限和疊加規則,優惠券可以無限疊加,結算金額算出來是負數。
這不是 AI 的錯。是我給的原料太糙了。
⚠️核心觀點:
並不是說,讓你必須在"低精度的規格文件"中就必須寫清楚所有的細節,而是利用AI海量的訓練資料,從AI替你做決定去實施,變成AI幫你判斷並提供更多方案,讓你去決定。
在把這份"低精度的規格文件"交給任何AI框架之前(OpenSpec、Superpowers、GSD等等),花半小時做一次深度優化,遠比事後花半天時間修 bug 劃算。
下面說說我從踩坑中總結的四個理由。
1. 自然語言天然就是充滿歧義
人與人溝通之所以高效,恰恰不是因為語言精確,而是因為我們有大量共用的背景知識。你說"幫我把門關上",對方預設你知道是哪扇門、什麼時候關、關到什麼程度。我們不需要把這些說全。
但 AI 沒有這些預設共識。AI 不像人能透過脈絡"揣摩"你的真實意圖,它只能按機率選擇最可能的解釋。而這個"最可能"的解釋,未必是你想要的。
- “支援批次匯入” —— 一次能匯入多少條?10條?10萬條?
- “資料即時更新” —— 毫秒級?秒級?還是每分鐘重新整理一次?
- “提高效能” —— 現有的效能基準是什麼?提高到多少算"提高"了?
這些問題在人類溝通中通常能透過後續對話補充,但如果規格文件本身就帶著這些缺口直接進入 AI 驅動的開發流程,缺口就會被 AI 用"合理的假設"填上。而這些假設,大概率不是你想要的。
2. OpenSpec/Superpowers 的提問澄清機制還不夠完善
我得承認,OpenSpec 和 Superpowers 這類規格驅動框架的想法是對的:拿不定主意就提問,不要自作主張。它們的提問機制確實也能幫我們補全一些遺漏的需求。
但實際用下來,我的感受是它們的澄清力度遠遠不夠。
我的體會
OpenSpec 或 Superpowers 的提問機制,有基本的追問意識,但深度和廣度都不夠,需要有人先把需求整理清楚,它才能在這個基礎上問出有價值的問題。否則,它連自己不知道該問什麼都察覺不到。
第一個問題:提問數量偏少。一個稍複雜的工程任務(比如"建置一個帶權限管理的訂單系統"),真正需要追問的細節少則二三十個,多則上百個。但 OpenSpec 通常只會提三五個問題就覺得自己"理解了"。它不會追著問:訂單金額超過多少需要特殊審批?權限被撤銷後正在處理的訂單怎麼處理?
第二個問題:AI 的理解帶有隨機性。同一個模糊的需求描述,同一個提問,在不同時刻得到的理解和回答可能就不一樣。甚至同一個問題,第一次他詢問我了,第二次卻什麼也不問,自作主張決定了。
第三個問題:提問的粒度太粗。比如欄位驗證規則、例外分支出理、介面逾時策略 ── 它一個都沒問。因為這些細節太細了,它從模糊的原始文件裡根本識別不出這些漏洞。
關於自然語言的歧義問題,我推薦在 意圖對齊:AI 時代編碼的核心工程能力 一文中有更深入的探討。
3. 細緻化掌控必須前置
有時候,我們對一個專案的實施細節有明確的掌控要求。不是"大概做出來就可以",而是"這裡必須這樣實現,那裡絕對不能那樣處理"。
掌控感來源於確定性
當你在文件階段就把細節釘死,AI 的執行路徑就變窄了。路徑越窄,偏離目標的可能性就越小。
舉個例子。一個支付模組的實現方案,如果你只告訴 AI"支援多種主流支付方式",它可能會自行決定:
- 同步還是非同步回呼
- 逾時時間多長
- 失敗後重試幾次
- 重試失敗後怎麼處理
- 是否引入防重播攻擊機制
這些決策本身沒錯,但你很可能已經對其中每一項都有明確要求。如果規格文件不提前寫清楚,等 AI 生成完方案再一個個去糾正,工作量反而加倍了。
我的做法是:在進入 OpenSpec 或 Superpowers 流程之前,先用一套系統化的規則,把規格文件的每個模糊點都打磨到足夠精確,就像本文開始時,我的核心觀點:"並不是說,讓你必須在"低精度的規格文件"中就必須寫清楚所有的細節,而是利用AI海量的訓練資料,從AI替你做決定去實施,變成AI幫你判斷並提供更多方案,讓你去決定"。這樣做的好處是:
- 減少 AI 的決策空間:細節越明確,AI 自行假設的機會越少
- 降低返工風險:方向在文件階段就對齊了,程式碼產出不會偏離太遠
- 提高審查效率:規格驅動產出的方案文件,品質本身也會更高,審查成本更小
4. 這套方法可以直接變成你自己的 Skill
最後一點,也是我認為非常有價值的一個方向:後面我描述的整套優化規則和實施流程,完全可以封裝成你自己的 Skill。
什麼意思呢?你不需要每次都手動按這套規則去檢查文件。你可以把歧義詞檢測規則、邏輯完整性檢查清單、優先順序標註規範、數量時間精確化對照表這些內容,全部寫進一個 Skill 或者 Prompt 樣板裡。之後任何新需求,只需要把原始規格(低精度的規格文件)丟進去,AI 就會自動按照你定義的規則做一輪優化。
這就像給自己的 AI 工具鏈裝了一個"需求品質把關器"。它不是要取代人類的判斷力,而是把那些重複的、容易遺漏的細節檢查環節自動化。
我的建議
如果你已經有一套自己的編碼規範 Skill(程式碼風格、目錄結構、註解規範等),不妨再加一個"規格優化 Skill"。它會在你進入實際編碼流程之前就發揮作用,幫你把輸入品質拉到足夠高的水準。輸入品質高了,後面的所有環節都會更順暢。
二、我是如何對一個低精度的規格文件進行優化的?
1. 核心優化規則
a. 歧義詞檢測與替換
這是優化的第一道關卡。自然語言天然存在大量表意模糊的詞彙,如果不加甄別直接使用,會導致AI或開發者產生多種理解路徑。
“和"的歧義:原文說"系統需要支援A和B功能”,這裡的"和"可能是並列關係(兩個功能都需要),也可能是指列關係(舉例說明)。改良方案:如果是並列需求,改為"系統必須同時支援A功能與B功能";如果是舉例,改為"系統需要支援A、B等功能"。
“或"的歧義:原文"使用者可以用微信或支付寶登入”,這裡的"或"是"二選一"還是"至少選一個都可以"?如果原意是使用者只能選擇其中一種方式,應改為"使用者只能在微信和支付寶中選擇一個方式登入";如果原意是兩種方式都支援但不強求同時使用,應改為"使用者可以使用微信登入,也可使用支付寶登入,至少支援其中一種"。
“如果"遺漏"否則”:原文"如果使用者連續輸錯密碼3次則鎖定帳號",但沒說如果沒輸錯3次怎麼辦、鎖定後如何解鎖。改良方案必須補充完整條件分支:“如果使用者連續輸錯密碼3次則鎖定帳號30分鐘;否則正常進入系統;鎖定期間滿後自動解除,使用者可重新嘗試。”
語氣詞模糊:“應該"和"盡量"是最容易被忽略的約束。“系統應該記錄日誌"和"系統必須記錄日誌”,前者給執行者留了"不記錄也不違規"的藉口,後者才是強制要求。改良時統一替換:強制場景用"必須”,建議場景用"優先",徹底消滅"應該/盡量"。
數量與時間模糊:“一些資料"“很多使用者"“盡快完成"“回應要快”──這類表達在執行層面沒有任何可操作性。必須轉化為具體的數值、範圍或時間指標。
b. 邏輯完整性檢查
一條完整的指令必須涵蓋所有可能的執行路徑,不能只描述一種路徑。
成功與失敗雙向涵蓋:原文"使用者提交訂單後儲存資料”,只說了成功流程。完整描述應為:“使用者提交訂單後,系統將資料儲存到資料庫;儲存成功則返回訂單號和成功提示;儲存失敗則返回具體錯誤原因,提示使用者稍後重試,同時記錄錯誤日誌供排查。”
正常流程與例外處理:原文"上傳檔案後解析內容”,但檔案超過大小限制怎麼辦?檔案格式不支援怎麼辦?上傳中斷怎麼辦?完整描述必須包含:檔案類型驗證、大小限制、逾時處理、網路中斷重試機制、解析失敗的使用者反饋。
能做與不能做:原文"管理員可以操作”,沒說哪些管理員、哪些操作、哪些情況不能操作。必須明確權限界限:哪些角色被排除在外?哪些操作被禁止?例如:“超級管理員可以刪除任何文章;一般管理員只能刪除自己發布的文章;所有管理員都不能刪除已歸檔的文章。”
預設行為定義:當所有條件都不滿足時,系統應該如何行動?原文必須明確定義:“如果使用者的角色不在上述清單中,預設僅擁有檢視權限,無法進行編輯或刪除操作。”
c. 優先順序與順序明確
當多個任務或規則並存時,如果不明確執行順序和優先順序,會導致執行混亂。
順序編號:原文說"先做A,再做B,順便做C",“順便"二字完全破壞了優先順序。改良後:“第一步:執行A操作 → 第二步:執行B操作 → 第三步:執行C操作。”
優先順序標籤:使用【必須】、【重要】、【可選】三級標籤強制區分約束強度。例如:
- 【必須】使用者密碼長度不少於8位
- 【重要】密碼應包含大小寫字母和數字
- 【可選】建議定期更換密碼(每90天)
判斷標準具體化:原文說"重要的事情先處理”,但"重要"是主觀判斷。必須給出具體標準:“當訂單金額超過1萬元或客戶等級為VIP時,視為高等級訂單,必須在2小時內處理;其他訂單按提交時間順序處理。”
d. 數量與時間精確化
模糊的數量和時間表達是需求失真的主要原因。
數量精確化對照表:
- “一些資料” → “不超過100筆資料”
- “很多使用者” → “同時線上使用者超過1000人時”
- “金額很大” → “單筆金額超過10萬元”
- “少數情況” → “發生率低於5%的場景”
時間精確化對照表:
- “盡快完成” → “在24小時內完成”
- “回應要快” → “首頁載入時間不超過3秒”
- “經常發生” → “每週至少發生3次”
- “一段時間後” → “延遲500毫秒後”
- “即時更新” → “資料重新整理間隔不超過30秒”
e. 角色與權限明確
權限描述模糊是安全風險的根源。
角色類型明確化:原文"使用者可以檢視",必須細化為:“一般使用者僅可檢視自己建立的訂單;付款使用者可檢視所有公開訂單;超級管理員可檢視所有訂單(包含已刪除的)。”
操作權限明確化:原文"有權限的使用者可以編輯文章",必須列出具體清單:
- 包含:修改文章標題、修改正文內容、增加或刪除圖片、更改分類和標籤
- 不包含:刪除文章(僅管理員可執行)、發布文章(需審核員審批)、修改作者資訊(僅作者本人可修改)
權限觸發條件:明確何時獲得、何時失去權限。“使用者完成實名認證後自動獲得編輯權限;帳號被封禁期間所有編輯權限立即凍結。”
2. 實施準則
- 不猜需求:有歧義先問澄清,不假設隱含需求,不按"常見做法"擅自添加未要求的功能
- 保持簡單:50行能解決不寫200行,不過度抽象,不創造不必要的抽象層/介面/工廠模式,優先使用現成方案
- 只做局部修改:嚴格限定修改範圍,不順手重構其他檔案,不統一命名風格,更改最小化
- 先定義"做成了":修bug先重現,加功能先定義驗收標準和測試方式,完成後必須運行驗證,有可驗證證據
- 分步實施,控制脈絡:大任務拆小步驟逐步完成,控制上下文不超過60%,過長主動建議新對話,避免AI記憶混亂和幻覺
- 註解和提交:程式碼必須編寫註解
- 分階段Git提交:每個邏輯單元完成後立即提交,格式:前綴: 描述。前綴規範:feat:新功能、fix:bug修復、refactor:重構、docs:文件、style:格式、test:測試、chore:組建配置
- Golang專案結構:新專案按標準layout(cmd/internal/pkg/api/configs/scripts/docs),舊專案保持現有結構一致性,不擅自規範化
- 防禦式程式設計(軟體任務必須):
- 參數驗證:所有外部輸入入口必驗證
- 空值處理:對可能為nil的值必檢查
- 錯誤處理:每個可能失敗的操作必須有明確錯誤處理路徑
- 邊界條件:陣列索引、字串長度、數值範圍必保護
- 預設值:配置項和可選參數提供合理預設值
- 失敗安全:部分元件失敗時降級運行,不完全崩潰
- 日誌記錄:關鍵操作和例外路徑必記錄
3. 實施流程
Step 1:詢問背景知識
- 先確認是否有可供調查的背景資料(專案程式碼、文件、知識庫)
- 有背景知識則讀取相關檔案,理解專案/業務脈絡,基於實際細節精準提問
Step 2:判斷是否加入TDD(軟體開發類任務)
- 涉及程式設計/程式碼實現/API開發時,詢問是否加入測試驅動開發要求
- 加入後提問補充測試類型、覆蓋範圍、邊界條件等問題
Step 3:選擇提問方式
- 極簡模式:1輪提問,每輪1-5個問題,適合問題明確/時間緊急
- 普通模式(推薦):1-3輪提問,每輪3-5個問題,平衡效率與深度
- 專業模式:3-5輪提問,每輪5-10個問題,深入全面涵蓋細節
Step 4:分析原文並多輪提問澄清
- 識別歧義詞彙、模糊表達、遺漏條件、隱含假設
- 提問簡潔精準,選項清晰易懂,標註推薦項,提供自訂回答
- 每一輪足夠清晰即可提前結束
Step 5:輸出優化方案
- 在原檔案同目錄建立
原檔名_優化版.md - 自動結構化重新排版,不添加額外資訊(評分/總結/版本等)
- 淨化文件輸出,可直接使用
三、最後
把規格文件優化做在前面這件事,我第一次系統性地實踐,效果比我預期的要好得多。
回顧一下全文的核心觀點:
第一,別指望 OpenSpec 或 Superpowers 能替你補全需求品質。 它們的提問機制是"錦上添花",不是"雪中送炭"。在模糊的原文基礎上提問,得到的答案也注定是模糊的。
第二,歧義不是小事。 自然語言裡的每一個模糊詞,在 AI 眼中都是一個可自由發揮的空間。“自動"“支援"“快速"這些詞在人類溝通裡無傷大雅,在規格文件裡就是埋雷。
第三,優化不是重寫。 你不需要把文件從三四行擴寫成三四千字。關鍵是消除歧義、補全分支、釘死邊界和數量。很多時候就是在關鍵地方加一個"必須”,把一個模糊詞換成具體數值,文件的品質就上一個台階。
第四,把它工具化。 整套規則寫成一個 Skill,讓它自動跑起來。一次配置,反覆使用,這才是工程思維。
第五,搭建一套自我進化的 LLM-Wiki。 這套優化規則不是一次性消耗品──每次踩過的坑、新發現的歧義模式、總結出來的校驗清單,都應該沉澱到你的個人知識庫裡。關於如何學習 Karpathy 的 LLM-Wiki 方法論並在實踐中應用,我詳細寫過一篇 學習 Karpathy 的 LLM-Wiki 方法論之後的自我實踐,介紹了這套方法:把 AI 會話中的碎片經驗提煉成結構化知識,再透過 wikilink 互聯形成知識圖譜。規格優化規則只是其中的一個節點,隨著你持續使用,它會越長越厚實,最終成為你自己的"工程資產庫”。
如果你還沒有做過類似的事情,我建議從今天開始就嘗試。拿一份你最近寫的需求文件,按照第二部分裡的規則逐項過一遍。你會驚訝地發現,那些以為"已經很清楚了"的地方,其實處處是坑。