
一、OpenSpecやSuperpowersを使用している場合であっても、なぜあらかじめ仕様書を最適化する必要があるのか?
このような要件があると仮定します。多くのプロジェクトで見たことがあるかもしれません:
アクティブ期間中にユーザーにクーポンを配布し、決済時に使用できるようにする。
一見問題ないように見えますよね?人間の読者はだいたい「察する」ことができます。しかし、これをそのままOpenSpecのワークフローに入れると、事態がずれ始めます:
- すべてのユーザーにクーポンを配布した(ブラックリストユーザーも含む)
- 1人あたりの上限が設定されておらず、同じユーザーが数千枚のクーポンを取得
- 有効期限や重複利用ルールがなく、クーポンが無制限に重複し、決済金額がマイナスになった
これはAIのせいではありません。私が用意した素材が荒すぎたのです。
⚠️コアコンセプト:
「低精度の仕様文書」で全ての詳細を書き記す必要は全くありません。代わりにAIの蓄積されたデータを活用し、AIが決定を実行してくれるのではなく、AIが判断を行い提案してくれて、自分が決定するように変えるのです。
「低精度の仕様文書」を任意のAIフレームワーク(OpenSpec、Superpowers、GSDなど)に渡す前に、30分かけて深く最適化する方が、後になって半日掛けてバグ修正するよりずっと得策です。
以下は私が失敗から学んだ4つの理由です。
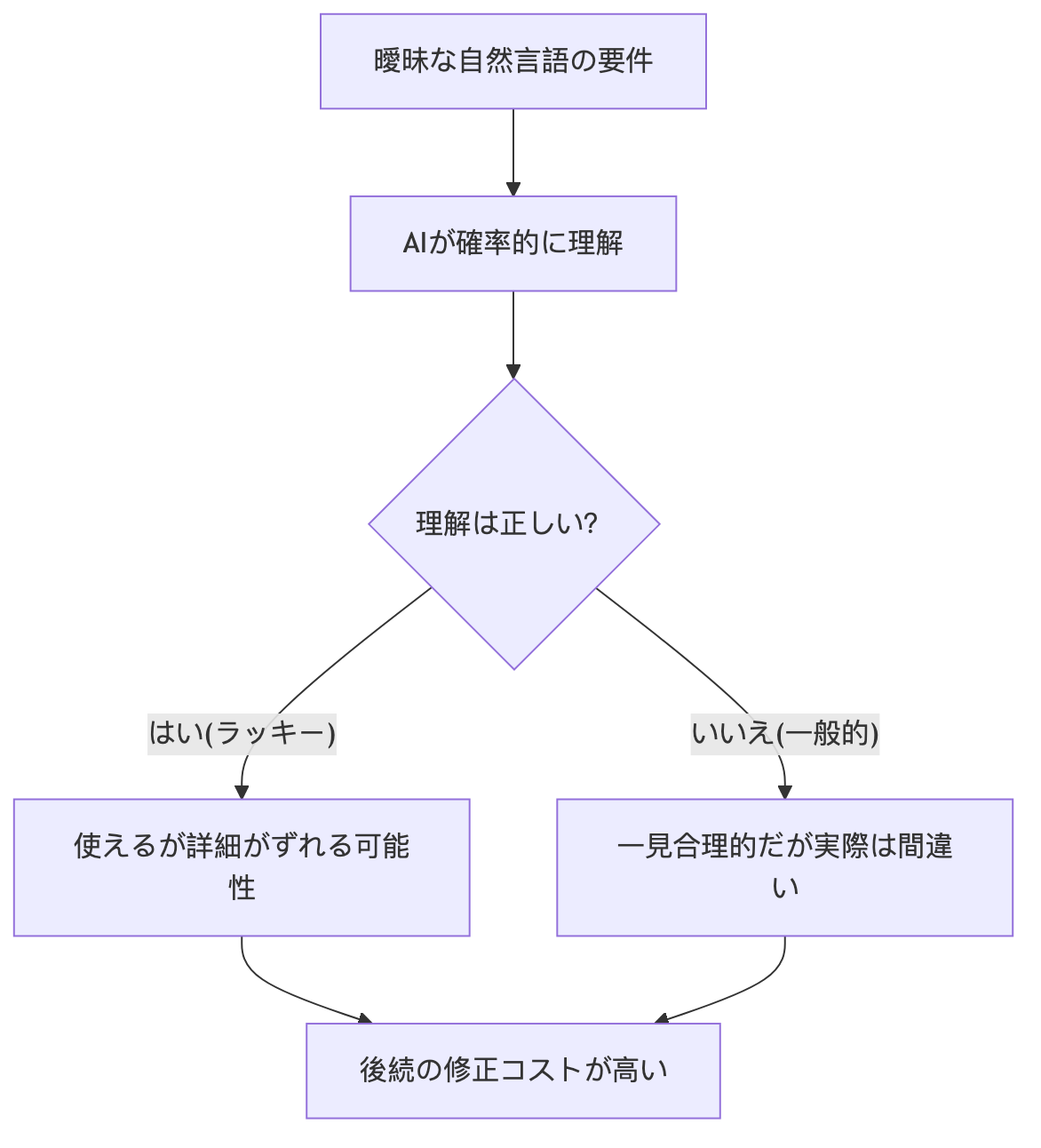
1. 自然言語は元々曖昧さに満ちている
人同士のコミュニケーションが効率的なのは言葉が正確だからではありません。共有された背景知識が大量にあるからです。「ドアを閉めてくれ」と言えば、相手は当然どこを指しているのか、いつ閉めるべきか、どのくらいしっかり締めるべきかなどを暗黙的に了解しています。これらを全部説明する必要はありません。
しかしAIにはこれらのデフォルトコンセンサスはありません。AIは人のように文脈を「察する」ことはできません。確率的に最も妥当な解釈を選択します。そしてこの「最も妥当」な解釈が、あなたの望むものであるとは限りません。
(AIと人間の意図アライメントについてはこちらに詳しく書きました)
- 「一括インポートをサポート」——一度に何件のデータをインポートできるのか?10件?10万件?
- 「データがリアルタイム更新される」——ミリ秒単位?秒単位?それとも1分ごとにリフレッシュ?
- 「パフォーマンスを向上させる」——現在のパフォーマンスベースラインは何か?どれくらい向上すれば「向上」となるのか?
これらの質問は人間同士の通信では通常、後続の会話で補足できます。しかし仕様文書がこうした抜け穴をそのままでAI駆動の開発プロセスに入った場合、抜ければAIが「合理的な想定」で埋められます。そしてその想定が、あなたの望み通りではない可能性が高いです。
2. OpenSpec/Superpowersの照会確認メカニズムはまだ十分ではない
私は認めます。OpenSpecやSuperpowersのような仕様駆動型フレームワークの考え方は正しいと思います:「不確かな場合は質問して」、独断専行してはならない。質問のメカニズムは確かに要求漏れを補うことに役立っています。
しかし実際やってみて感じるのは彼らの確認の強度ははるかに不十分であるということです。
私の感触
OpenSpecやSuperpowersの問い合せメカニズムには基本的な追問意識はあるが、深さと広さは不十分です。誰かがまず要求を整理して初めて、それにより価値のある質問ができることになります。それ以外の場合、「自分で質問すべきことが分からない」という自覚もないかもしれません。
最初の問題:質問数が少ないです。少々複雑な工事タスク(例えば「権限管理付き注文システムを作成する」など)にとって、本当に追問が必要な詳細は最低でも20〜30個以上、多いとHundredsもあります。しかしOpenSpecは通常3〜5個の質問があれば「理解した」と思ってしまいます。それは追及して質問しません:注文金額がいくらを超えると特別承認が必要なのか?権限が剥奪された後で処理中の注文はどうするのか?などの質問です。
二番目の問題:AIの理解にランダム性があります。同じ曖昧な要件記述、同じ質問に対しても異なる時間帯に答えが異なるかもしれません。さらにはある問題に対して初回は私に訊きましたが、2回目は何も訊かずに勝手に決めてしまいます。
三番目の問題:質問の粒度が粗すぎます。フィールド検証ルール、例外分岐処理、インターフェースタイムアウト戦略 — 全く訊かないのであります。これらの詳細すぎるため、あからさまな原文からはこれらの漏れを見逃してしまうのです。
3. 細かい粒度の制御は事前に準備しなければならない
時折、プロジェクト実装の詳細について明確な制御要求を持っていることもあります。「概ね形になるだけでいい」ではなく、「ここは必ずこう実装する」「そこは絶対にこうすることはしない」ということです。
コントロール感は確実性から来る
ドキュメント段階で詳細を明確にしておくと、AIの実行パスが狭くなります。パスが狭ければ狭いほど、目標から逸れる可能性も小さくなります。
例を挙げましょう。支払いモジュールの実装計画を立てるとします。AIに「主要な支払い方法を複数サポートする」とだけ伝えた場合、AIは次のように自在に決定してしまいます:
- 同期または非同期コールバック
- タイムアウトまでの時間設定
- 失敗後のリトライ回数
- リトライ失敗後の処理
- リプレイ防止システムの導入の可否
これらの決定自体は間違いではありませんが、おそらくそれぞれに対してすでに明確な要求をお持ちです。仕様文書が前提として明確に書かれていない場合、AIがプラン作成後に一つひとつ訂正するのは手間が倍増してしまいます。
私のやり方は:OpenSpecやSuperpowersのプロセスに入る前に、まず体系的なルールに従って仕様文書の各曖昧なポイントを十分正確にブラッシュアップすることです。冒頭で述べた私の核心的見解:「低精度の仕様書ですべてを明確にする必要は全くない。AIの豊富な訓練データを利用して、AIが判断を行い、提案してくれて、自分が決定できる状態にすることです。」これのメリットは:
- AIの決定空間が減少する:詳細が明確になればなるほど、AIが勝手に推測する機会は減ります
- 再作業リスクの低減:文書段階で方向性が揃えれば、コード出力は大幅に逸脱しません
- レビュー効率の向上:仕様駆動で生み出されるプラン文書自体の品質も高くなり、審査コストが安くなります
4. これらの方法をスキルとして自身でもカスタマイズできる
最後にもう一点。私は非常に価値があると考える方向です:以下に述べる最適化ルールと実施プロセス全体を独自スキルとしてカプセル化すれば良い。
どういうことでしょうか?ドキュメントを毎回マニュアルでチェックする必要はありません。曖昧語検知ルール、ロジック完全性チェックリスト、優先度タグ付け規則、数量・時間の精度化対応表などを全部スキルやプロンプトテンプレートに書き込みます。新しい要件を出す際には、単に元の仕様(低精度仕様書)を入れれば、AIは自動的に自分の定義ルールで最適化を実行します。
まるで自分のAIツールに「要件品質のゲートキーパー」を組み込んでいるようなものです。人間の判断力を代替するのではなく、反復的で見逃されやすい詳細検査部分を自動化するのです。
私の提案
既に自分自身のコーディング規約スキル(コードスタイル、ディレクトリ構造、コメント規則など)があるならば、「仕様最適化スキル」をもう一つ追加してみてはいかがでしょう。実際のコーディングプロセスに入る前から作用し、入力品質を十分高い水準に引き上げてくれます。入力品質が高くなれば、その後のすべてがスムーズになります。
二、低い精度の仕様ファイルをどう最適化するか
1. 核心的な最適化ルール
a. 曖昧語検知と置換
これは最適化の第一関門です。自然言語には意味があいまいな語句がたくさんあり、吟味せずに使うとAIや開発者が解釈に困ることがあります。
「および」のあいまい性:原文「システムはAかつB機能をサポートする必要があります」では、「および」は並列関係(両方の機能が必要)とも列挙関係(例を示している)とも受け取れます。改善案:並列の場合は「システムはA機能とB機能の両方をサポートしなければなりません」。例の場合は「システムはA、Bなどの機能をサポートする必要があります」。
「または」のあいまい性:原文「ユーザーはWeChatまたはAlipayでログインできます」において、「または」は「2択」なのか「少なくともいずれか1つ選べる」のかという点です。元の意図がユーザーがどちらか1つのみ選ぶことを想定しているとすれば、「ユーザーはweChatとAlipayの中から1種類のログイン方法のみ選択できます」、2つの方式をサポートするが同時使用は必須でないとする場合は、「ユーザーはWeChatでログイン可、またAlipayでのログインも可能であり、少なくとも一方をサポートします」。
「もし」に「そうでなければ」の欠如:原文「ユーザーが連続してパスワードを3回間違えたらアカウントをロックする」とありますが、3回間違ってない場合どうするか、ロックされた後にどう解除するかが書かれていません。改善案では条件分岐を補う必要があります:「ユーザーが連続してパスワードを3回間違えた場合、アカウントは30分ロックされます。そうでなければ正常にシステムに入ります。ロック時間が終了すれば自動的に解除され、ユーザーは再び試すことができます。」
語気詞のあいまいさ:「べき」と「できるだけ」は最も軽視されやすい拘束力です。「システムはログを記録するべき」ことと「システムはログを記録しなければならない」こと、前者は「記録しないことも違反にはならない」という口実を与えるのに対し、後者が強制的な要請になります。改善時には統一して置換し、強制的なケースには「必須」、提案的な場面には「優先」にし、「すべき/できるだけ」を徹底的に排除します。
数量・時間のあいまいさ:「いくつかのデータ」、「多数のユーザー」、「できるだけ早く終わらせる」、「応答は速い必要がある」など——このような表現は動作面上、一切の操作性を持ちません。具体的な数値、範囲、時間指標へと変換しなくてはなりません。
b. ロジック完全性チェック
完璧な命令文はすべての実行経路を網羅しなくてはならず、1つのパスonlyを記述してはいけません。
成功と失敗の双方向カバー: 原文「ユーザー注文を提出後にデータを保存する」で、成功ケースしか説明していない。完全な記述は「ユーザーが注文を送信すると、システムはデータをデータベースに保存します。保存が成功した場合、注文番号と成功の表示を返します。保存が失敗した場合は具体的なエラー内容を返し、ユーザーに少し待って再試行するよう表示し、同時にエラーログも記録します。」
通常プロセスと異常Handling: 原文「ファイルアップロード後、内容を解析する」。ファイルがサイズ制限を超えていたら?ファイル形式がサポートされていなければ?アップロードが途中で止まったらどうするのか?完全な記述は次のものを含む必要があります:ファイル種類の検証、サイズ制限、タイムアウト処理、ネットワーク切断時の再試行メカニズム、解析失敗時のユーザーへのフィードバック。
やれることとやれないこと: 原文「管理者は操作ができる」が、どんな管理者がどんな操作をするのか、どんな状況で操作をしてはならないか、示されていません。権限境界を明確にする:どの役割が除外されているのか?どの操作が禁止されているのか?例:「スーパーアドミンはすべての記事を削除できます。通常管理者は自分で掲載した記事のみを削除できます。すべての管理者はすでにアーカイブされた記事を削除できません。」
デフォルト行動の定義: すべての条件に合わないとき、システムはどう動くべきか?原文には明確に定義が必要:「ユーザーの役割が上述のリストに存在しない場合、標準では表示権限のみを持ち、編集や削除はできないことになっております。」
c. 優先度と順序の明確化
複数のタスクやルールが同時に存在する場合、実行順序と優先度を明確にしないと実行に混乱が生じます。
順序番号: 原文では「A→B→Cをついでに実施」ですが、「ついでに」という語句は優先を完全に損なっています。改善後:「STEP1:A操作を実施 → STEP2:B操作を実施 → STEP3:C操作を実施」
優先度タグ付け:【必須】、【重要】、【任意】を使用して制約の強度を区別します。例:
- 【必須】ユーザーパスワードは最低8文字以上であること
- 【重要】パスワードが大文字、小文字、数字を含んでいなければならない
- 【任意】パスワードを定期的に変更することを推奨します(90日ごと)
判断基準の具体化: 原文「重要なことを先に処理」では、「重要」というのは主観的な判断です。客観的基準を与えなければならない:「注文額が1万円を超えるか顧客レベルがVIPの場合、高優先度注文とみなされ2時間以内に処理しなければいけません。他の注文は提出時間通りに処理。」
d. 数量と時間の精度化
あいまいな数量・時間の表現は要件乖離の主な原因となります。
数量精度化対照表:
- 「いくつかのデータ」 → 「100件以上のデータ」
- 「多くのユーザー」→「同時にオンラインのユーザーが1000人以上の場合」
- 「大きな額」 →「1件当たり10万元以上」
- 「まれなケース」→「発生頻度が5%以下のシナリオ」
時間精度化対照表:
- 「できるだけ早く完了」 → 「24時間以内に完了」
- 「迅速に反応」 → 「初期画面の読み込みが3秒以内」
- 「頻繁に行う」 → 「週に最低3回」
- 「一定時間が経過した後」 → 「500ミリ秒遅延後」
- 「リアルタイム更新」 → 「データ更新間隔30秒以内」
e. ロールと権限の明確化
権限の記述があいまいなことはセキュリティ事故の根本原因です。
ロール種別の明確化: 原文「ユーザーが閲覧できる」は、「一般ユーザーは自分自身が作成した注文のみ閲覧可能。有料ユーザーはすべての一般注文を閲覧可能。スーパーアドミンはすべての注文を閲覧可能(削除されたものも含む)」のように細分化しなければなりません。
操作権限の明確化: 原文「適切な権限を持つユーザーは記事を編集できます」は、具体的なリストを作る:
- 包含:記事タイトルの変更、正文内容の変更、画像の追加・削除、カテゴリーとタグの変更
- 除外:記事の削除(管理者のみ実行できます)、記事の公開(審査員の承認が必要)、著者情報の変更(作成者のみ変更可)
権限発生条件: いつ獲得するのか、いつ失うのかを明確にする。「ユーザーが実名認証を完了後、自動で編集権限が付与されます。アカウントが停止している間はすべての編集権限を即座に凍結。」
2. 実施基準
- 要件を当て推量しない:曖昧であればまずは確認を求める、潜在的な要件を想定しない、一般的な方法に従って求めていない機能を独自追加しない
- 簡潔に保つ:50行で終わるなら200行にしない、過剰に抽象化せず、無駄な抽象層/インターフェース/ファクトリパターンを作らず、既存ソリューションを優先
- 局所的な変更とする:厳守変更範囲を限定、他のファイルのリファクタリングを手癖で行わず、命名規則を統一せず、変更を最小限に留める
- 「完了」の定義をあらかじめ行う:Bug修正はまず再現する、新機能追加は最初にacceptance基準とテスト手順を定義する、完了後は実行と検証を行う、検証可能な証拠を得る
- 段階的に実施し、コンテキスト管理:大規模タスクを小さなステップに分割して徐々に完了、コンテキストが60%を超えないように意識、長くなった場合は新規セッションを提案してAIのメモリ混乱と幻覚を避ける
- コメントとコミット:コードはコメントを絶対に付ける
- 段階的なGitコミット:各ロジックユニット完了後は直ちにコミット、フォーマット:Prefix: Description。Prefixは規定:feat:新機能、fix:Bug修正、refactor:リファクタリング、docs:ドキュメント、style:フォーマッティング、test:テストコード、chore:ビルドや設定
- Golangプロジェクト構造:新プロジェクトはstandard layoutに従う(cmd/internal/pkg/api/configs/scripts/docs)、旧プロジェクトは構造の一貫性を維持する、勝手に標準化はしない
- 防御プログラミング(ソフトウェア関連は必須):
- パラメータ検証:すべて外部入力は検証必須
- Null値処理:nilになりうる値はすべてチャック必須
- エラー処理:失敗する可能性のある操作に対し、エラー処理パスを明確に
- 境界条件:配列アクセス、文字列長、数値範囲保護必須
- デフォルト値:設定項目とオプションパラメータに対し、合理的な初期値提供
- Fail-safe:一部コンポーネントの故障時のフォールバック動作、完全なクラッシュは避ける
- ログ記録:キーオペレーションと例外は記録必須
3. 実施プロセス
ステップ1:背景情報を確認
- 調査できる背景資料が既に存在するか(プロジェクトコード、ドキュメント、知識ベース)
- 背景資料があれば関連ファイルを読み込み、プロジェクト/ビジネスの文脈を把握し、実際の詳細に基づいた正確な質問を行う
ステップ2:TDDを追加するかどうか判断(ソフトウェア開発関連)
- プログラミング/コード実装/API開発に関連する場合、テスト駆動開発の導入を確認
- 導入する場合は補足的なテストタイプ、カバレッジ範囲、境界条件などの質問を行います
ステップ3:質問方法を選択
- 最小モード:1巡の質問、各巡1〜5問、問題意識明確/短期間の時適する
- 標準モード(推奨):1〜3巡の質問、各巡3〜5問、効率と深さのバランス
- 専門モード:3〜5巡の質問、各巡5〜10問、詳細を深く包括的にカバー
ステップ4:原文を分析して複数回にわたって質問・明確化
- 曖昧語彙、不明瞭表現、不足条件、隠れた前提の識別
- 簡潔かつ正確な質問、明確なオプション、推奨項目を表示、カスタム回答を提供
- 各ラウンドで十分に明確であれば早期終了
ステップ5:最適化プラン出力
- 元ファイルのディレクトリに
元ファイル名_最適化版.mdを作成 - 自動構造再レイアウト、追加情報(評価/要約/バージョンなど)は追加しない
- 純粋ドキュメント出力、そのまま使用可能
三、終わりに
事前に仕様最適化を行うこと。私は体系的に実施したことはなかったが、結果は予想よりはるかに良かった。
改めて全文の中心概念をおさらいしましょう:
第一に、OpenSpecやSuperpowersが要件品質を補ってくれることを期待してはいけません。 彼らの質問機能は「錦上添花」であって「雪中送炭」ではありません。あいまいな原文に基づいて質問しても、得られるのはやはりあいまいなものです。
第二に、曖昧さは些細なことではありません。 自然言語の中に含まれるすべてのあいまい言葉は、AIにとっては自由に解釈できる空間です。日本語で「自動」「対応」「迅速」は人間同士の会話では問題なくても、仕様書では危険な「地雷」を仕込んでいます。
第三に、最適化は全面改正ではありません。 文書を3〜4行から3〜4000行に書き直す必要はありません。重要なのは、あいまいを消去し、分岐を補完し、境界や数量の線引きを明確にすることです。多くは、キーとなる箇所に「必須」を付け加えたり、曖昧語を具体的数値に置き換えたりするたけで、文書の品質は大きく向上します。
第四に、それをツール化しましょう。 全てのルールをスキルにし、自動実行させましょう。設定は一瞬だけで繰り返し利用できる。これこそがエンジニアリング思想です。
第五に、自分独自の進化可能なLLM-Wikiを構築してください。 この最適化ルールは使い捨ての消耗品ではありません——踏んだ穴、発見した曖昧なパターン、まとめ上げた検査リストはすべて個人の知識庫に蓄積すべきです。私は『KarpathyのLLM-Wikiメソドリを学習後での自己実践』でこの手法を詳しく書いています。AI会話の中の断片的な経験を構造的知識に抽出し、wikilinkで相互接続して知識グラフを形成。仕様最適化ルールはその中のノードの1つでしかありません。継続的に利用することで、ますます充実し、最終的にはあなた自身の「エンジニア資産ライブラリ」になります。
もしまだこうしたことを実施したことがない場合は、今日から実践してみてください。最近書いた要件文書を1つ取り出し、第2部のルールに沿って1項目ずつ見直してみてください。以前「十分明確だと思っていた」のに、実はいたるところに罠があることに驚くことでしょう。(KarpathyのLLM-Wikiメソドロジーについてはこちらに書きました)