
一、AI 时代的开发范式转变
当我们谈论"Vibe Coding"时,我们指的不是某种新的编程语言或框架,而是一种全新的开发范式——AI 驱动的交互式编程。在这个时代,代码不再是开发者独自敲击键盘的产物,而是人与 AI 持续对话、协作探索的结果。这代表了软件开发方式的一次重大范式转变。然而,这种范式转变却暴露了传统 Git 工作流的深层瓶颈。
1. 单一 working directory 的限制
传统 Git 假设一个仓库只有一个工作目录。但在 AI 辅助开发中,我们需要同时进行多个方案、测试不同实现路径,单一工作目录根本无法满足需求。
2. 分支来回切换,影响多个层面:
- stash 的痛苦:切换分支前必须 stash 修改,但 AI会话 不知道这些文件被藏起来了
- commit 的压力:频繁创建临时 commit 污染提交历史
- context 丢失:切换后,AI会话 积累的上下文(对话历史、理解的项目结构)瞬间清空
3. AI会话的上下文是有逻辑关系的
会话A -> 会话B -> 会话C 其实是有先后逻辑顺序的,并且这些会话不是简单的命令执行器,它承载着:
- 对话历史:理解用户意图的完整链条,AI可以去获取这些会话的历史
- 文件状态认知:AI"知道"当前文件的结构、依赖关系
- 思维链:多次迭代中积累的推理过程,并且AI会去读取git commit的先后关系,代码是如何演进的。
切换分支会打断这一切,相当于给 AI"换脑"。最致命的是:无法并行探索多个方案。在传统模式中,如果你想尝试三种不同的架构方案,只能串行:探索方案 A → reset → 探索方案 B → reset → 探索方案 C。这种低效的迭代模式与 AI 快速探索的能力形成巨大的矛盾。
二、Git Worktree 机制解析
1. Worktree 是什么
从技术定义来看,Git Worktree 是一个共享 .git 仓库的多 working directory 机制,从某些工作目录,派生出更多不同的工作目录,但这些目录又通过 branch 彼此关联。
- 共享 repository:所有 worktree 共享同一个
.git目录,共享完整的 commit history、refs、objects - 独立工作目录:每个 worktree 有自己的文件系统目录,可以独立 checkout 不同分支,比如,项目/path/to/ProjectA,派生出/path/to/ProjectA-fix-bug、/path/to/ProjectA-new-feature
- 分支独占性:一个 branch 在同一时刻只能在一个 worktree 中被 checkout
与 clone 的区别:
|
|
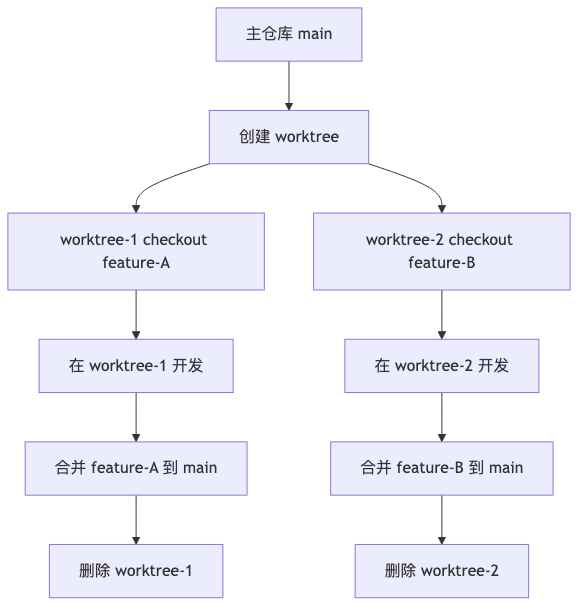
2. Worktree 的生命周期
3. 基础命令
|
|
实用参数组合:
-b <branch>:在创建 worktree 时同时创建新分支--detach:创建游离 HEAD 状态的 worktree(适合临时实验)--lock:锁定 worktree,防止被 prune 清理
建议将 worktree 命名与分支名保持一致,例如:
|
|
三、为什么 Vibe Coding 需要 Worktree
1. AI会话的本质需求
上下文完整性:AI会话 不是原子化的命令执行,而是连续的对话流。
- 用户:“帮我重构这个模块”
- AI:“我分析了依赖关系,建议分三步…”
- 用户:“第二步看起来有问题”
- AI:“你说得对,让我重新设计…”
这段对话中,AI 积累了:
- 对项目的结构理解
- 对用户偏好的认知
- 对之前尝试方案的记忆
切换分支会打断这个链条,AI 需要从零重新建立上下文。
工作环境稳定性:AI 需要稳定的文件状态来工作。如果文件被 stash 或 reset,AI 的"认知地图"就失效了:
- “我记得
auth.ts的 API 接口是…怎么文件不见了…” → 文件被 stash,AI 找不到它 - “奇怪,我们之前修改了…” → 修改被 reset,AI"记忆"失效
探索自由度:AI 辅助开发的核心优势是快速迭代探索。但探索需要:
- 实验性修改不影响主分支,或者说主线(baseline)、主路径
- 多个方案可以并行存在
- 失败的尝试可以随时丢弃
传统 Git 的单一工作目录无法满足这些需求,可能在反复切换中,造成管理混乱。
2. 传统模式的痛点
🔴 痛点1:切换分支 = 丢失 AI 上下文
场景:你在
develop分支用 AI 开发 feature-A,突然收到紧急 Bug 修复请求。传统做法:
- stash 当前修改
- checkout hotfix 分支
- 启动新的 AI会话 处理 bug
- 修复完成,checkout 回 develop
- stash pop 恢复修改
问题:原 AI会话 已丢失,需要重新解释 feature-A 的设计思路
🔴 痛点2:AI 修改文件 = stash 后 AI 找不到文件
AI 正在修改
config.ts,你突然需要切换分支。你 stash 修改,切换分支,但 AI 不知道文件被藏起来了:
- AI:“我继续修改
config.ts…”- 实际:文件已被 stash,AI 在旧版本上修改
结果:修改错乱,stash pop 时产生冲突
🔴 痛点3:探索性修改 = 污染主分支或频繁 reset
AI 尝试三种架构方案:
- 方案 A:修改 10 个文件
- 发现问题,reset 回起点
- 方案 B:修改 8 个文件
- 又发现问题,reset
- 方案 C:修改 12 个文件
结果:主分支被频繁 reset,commit 历史混乱,或者不敢 commit 导致文件状态无法回溯。
🔴 痛点4:无法并行 = 只能串行尝试不同方案
你想同时让:
- AI-1、AI-2 一起开发前端风格方案A和风格方案B,最后二选一
- AI-3、AI-4 一起探索后端不同算法的性能方案,最后二选一
- AI-5、AI-6 一起探索不同数据库 schema 方案,最后在查询效率和存储成本之间,寻找最优方案
传统模式:只能串行。AI-1 探索 → reset → AI-2 探索 → reset → AI-3 探索 效率损失:3 个 AI 本可并行,却被强制串行,浪费了 AI 的快速迭代能力。
四、实践的总结
1. 场景的简介
你需要在同一时间开发三个独立功能:
- Feature-A:用户认证模块
- Feature-B:性能优化
- Fix-C:修复某个紧急BUG
传统困境:只能串行开发,每个功能完成后才能开始下一个。
Worktree 解决方案:
|
|
2. 管理规范
命名约定
- 功能性 worktree:
project-feat-{feature-name} - 探索性 worktree:
project-exp-{approach-name} - 修复性 worktree:
project-fix-{issue-number}
保持命名一致性,便于管理和识别。
目录结构建议
|
|
3. 清理与维护
清理:
|
|
删除 worktree 前确认
- 对应分支是否已 merge 到 main-repo
- 是否有未提交的重要修改
- 是否有依赖此 worktree 的进程(如正在运行的 AI会话)
五、结语
Git Worktree 不是简单的技术技巧,而是适配新开发模式的系统性解决方案。传统 Git 工作流诞生于"单人连续工作"的时代,而 Vibe Coding 是"多 AI 并行、快速探索、上下文敏感"的新时代。Worktree 恰好弥补了传统工具与新范式之间的鸿沟。
当你开始使用 Worktree 后,你会发现:
- 并行探索成为常态:多 AI 同时工作,效率倍增
- 实验不再污染主分支:大胆尝试,随时丢弃,主仓库始终保持干净