
はじめに:AI時代の開発パラダイムシフト
「Vibe Coding」という言葉は、特定のプログラミング言語やフレームワークを指しているわけではありません。指しているのはAIを相手に対話し、一緒にコードを書くという、まったく新しい開発のやり方です。これまでコードは開発者が一人でキーボードを叩いて作るものでしたが、これからは人間とAIが会話しながら、試行錯誤を重ねて作っていくものになります。ソフトウェアの開発そのものが変わろうとしているのです。
ただ、この変化に合わせて既存の Git ワークフローを見直そうとすると、いくつか根本的なボトルネックにぶつかります。
1. 作業ディレクトリが1つしかない制約
Git はもともと「1リポジトリにつき作業ディレクトリは1つ」を前提に作られています。しかし AI に手伝ってもらいながら開発していると、複数のアイデアを同時に試したい、別の実装パスを比較したいといった場面が頻繁に起きます。作業ディレクトリが1つでは、とても追いつきません。
2. ブランチを切り替えるたびに起きること
ブランチを切り替えるのは一見単純な操作ですが、実際には複数のレベルで影響が出ます。
- stash への依存:切り替える前に変更を stash しておかなければなりませんが、AI はそのファイルが退避されたことを把握できません。
- コミットへの心理的ハードル:確認用の一時コミットを繰り返せば履歴が汚れ、コミットをためらえば作業状態を失います。
- コンテキストの消失:切り替えた瞬間、AI セッションが積み上げてきた文脈(会話の流れやプロジェクトの理解度)がリセットされます。
3. AI セッションには「連続性」がある
セッションA → セッションB → セッションC は単なるコマンドの羅列ではありません。前後の文脈につながりがあり、AI はその中で以下のものを保持しています。
- 会話の履歴:どこまで話し合って、どの方向に話が進んだか。
- ファイルの構造認識:今どのファイルがどういう状態か、どこがどこに依存しているか。
- 思考のプロセス:何度か試行錯誤する中で「なぜこのやり方を選んだか」。Git のコミット履歴も読んで、コードがどう変化してきたかを追っています。
ブランチを切り替えると、これらがすべて断ち切られます。AI にしてみれば、脳の中枢を入れ替えられているようなものです。そして何より困るのが複数のアイデアを並列で試すことができないという点です。従来なら アプローチA を試して → reset → アプローチB を試して → reset → アプローチC を試して、という直列の作業しかできませんでした。AI の強みである「とりあえずやってみる」スピードが、Git の制約で殺されてしまっています。
Git Worktree の仕組み
Worktree とは何か
一言で言えば、1つの .git リポジトリから複数の作業ディレクトリを生やすための仕組みです。ディレクトリはそれぞれ独立していますが、ブランチを通じて同じ履歴を共有しています。
- リポジトリの共有:すべての worktree が同じ
.gitを参照します。コミット履歴も、refs も、オブジェクトも共通です。 - 独立した作業ディレクトリ:それぞれに独立したパスを持ち、別々のブランチを checkout できます。たとえば
/path/to/ProjectAから/path/to/ProjectA-fix-bugや/path/to/ProjectA-new-featureを派生させるといった形です。 - ブランチの排他制御:同じブランチを複数の worktree で同時に checkout することはできません。
clone との違い:
|
|
Worktree のライフサイクル
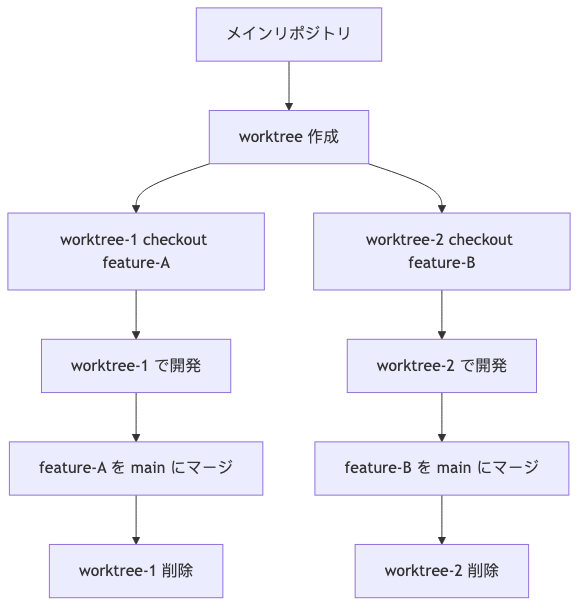
基本コマンド
|
|
よく使うオプション:
-b <branch>:worktree の作成と同時にブランチを作る--detach:detached HEAD 状態で作る(使い捨ての実験向け)--lock:prune での誤削除を防ぐためにロックする
worktree のディレクトリ名はブランチ名と揃えておくのが無難です。
|
|
AI と一緒に書くなら Worktree が必要な理由
1. AI セッションが本当に必要としているもの
文脈の连贯性:AI とのやりとりは単発のコマンド実行ではありません。会話の連続体です。
- 開発者:「このモジュール、リファクタリングお願い」
- AI:「依存関係を整理して、3段階に分けてやるのがよさそうです」
- 開発者:「2段階目のやり方、ちょっと怪しくない?」
- AI:「たしかに。設計を見直します」
このやりとりの過程で、AI は以下のようなものを蓄積しています。
- プロジェクトの構造への理解
- 開発者が好みそうな設計の方向性
- これまで試してダメだったパターン
ブランチを切り替えると、この積み上げてきたものがいったんゼロに戻ります。
ファイル環境の安定:AI は「今ファイルがこういう状態にある」という認識を前提に動きます。stash や reset でファイルが変わってしまうと、その「認知マップ」が壊れてしまいます。
- 「
auth.tsのAPI設計はこうだったはず……あれ、ファイルがない?」 → stash で退避されていた。 - 「さっき直したばかりなのに……」 → reset で戻ってしまった。AI の「記憶」と現実がずれる。
実験の自由度:AI を使う最大のメリットは、短いサイクルで何度でも試せることです。しかしそのためには以下の条件が必要です。
- 実験用の変更がメインのブランチに影響しない
- 複数のアイデアを並行して置いておける
- うまくいかなかったものは、ペナルティなしで捨てられる
作業ディレクトリが1つでは、どれも実現できません。ブランチを行き来しているうちにあっという間に管理が破綻します。
2. 従来のやり方では辛いポイント
🔴 ポイント1:ブランチ切り替え = AI の文脈がリセット
シチュエーション:
developブランチで AI と feature-A を開発中、急ぎのバグ修正依頼が入った。従来のやり方:
- 変更を stash
- hotfix ブランチに checkout
- AI セッションを新しく立ち上げてバグ対応
- 修正完了後、
developに checkout で戻るstash popで作業を復元問題点:最初の AI セッションは消えており、feature-A の設計を最初から説明し直す必要がある。
🔴 ポイント2:AI がファイルを編集中に stash =AI がファイルを見失う
AI がまさに
config.tsを編集している最中に、ブランチ切り替えが必要になった。変更を stash してブランチを切り替えるが、AI はそのことを知らない。
- AI:「
config.tsの編集を続けます……」- 実際:ファイルは stash 済み。AI は一つ前のバージョンを編集しようとしてしまう。
結果:
stash popのタイミングでコンフリクトが起きる。
🔴 ポイント3:実験的な変更 =メインブランチの汚れと reset の繰り返し
AI が3つのアーキテクチャを試す:
- アプローチA:10ファイルを編集
- 問題発覚。起点に reset
- アプローチB:8ファイルを編集
- こちらもダメ。また reset
- アプローチC:12ファイルを編集
結果:メインブランチへの reset が繰り返され、コミット履歴がぐちゃぐちゃになる。コミット自体をためらっていると、作業の途中状態を振り返ることすらできなくなる。
🔴 ポイント4:並列実行できない =アイデアを順番にしか試せない
やりたいこと:
- AI-1 と AI-2 にフロントエンドのデザイン案A・Bをそれぞれ作ってもらい、見比べたい
- AI-3 と AI-4 にバックエンドのアルゴリズムを比較検討させたい
- AI-5 と AI-6 にデータベーススキーマの案を出してもらい、検索性能とストレージコストのバランスを探りたい
従来のやり方:直列でしか回せない。AI-1 → reset → AI-2 → reset → AI-3。 もったいない点:本来並列で動かせる3つの AI を、わざわざ順番待ちさせている。AI の高速な試行錯誤という利点を、みずから潰しているようなものです。
実践:Worktree でどう解決するか
1. 具体的シチュエーション
同時に3つの機能開発を進めたい場合:
- Feature-A:認証機能
- Feature-B:パフォーマンス改善
- Fix-C:緊急性の高いバグ修正
従来のやり方:ひとつずつ完了させていくしかありませんでした。
Worktree を使ったやり方:
|
|
2. 命名規則とディレクトリ構成
命名ルール:
- 機能開発用:
project-feat-{機能名} - 実験用:
project-exp-{アプローチ名} - 修正用:
project-fix-{チケット番号など}
ルールを揃えておくと、ディレクトリ名を見ただけで何の作業用かが分かります。
推奨するディレクトリ構成:
|
|
3. 掃除とメンテナンス
掃除の流れ:
|
|
worktree を消す前のチェックリスト:
- 対応するブランチは main に merge 済みか
- コミットしていない重要な変更はないか
- その worktree に依存している処理(動作中の AI セッションなど)はないか
まとめ
Git Worktree はちょっとした小技ではありません。開発のやり方が変わった時代に、ツール側をそれに合わせるための仕組みです。 従来の Git ワークフローが「1人の開発者が1本の作業を続ける」ことを前提に作られていたのに対し、Vibe Coding は「複数の AI が並列で動き、高速に試し、文脈を保ちながら進む」時代です。Worktree はそのギャップを埋めてくれます。
実際に Worktree を使い始めると、以下の変化に気づくはずです。
- 並列での実験が当たり前になる:複数の AI が同時に動き、開発の速度が上がります。
- 実験がメインブランチを汚さなくなる:思い切って試して、ダメなら捨てる。メインリポジトリは常にきれいな状態を保てます。