
Vibe Coding 時代的 Git Worktree 實踐指南
前言:AI 時代的開發範式轉變
當我們談論「Vibe Coding」時,我們指的不是某種新的程式語言或框架,而是一種全新的開發範式——AI 驅動的互動式程式設計。在這個時代,程式碼不再是開發者獨自敲擊鍵盤的產物,而是人與 AI 持續對話、協作探索的結果。這代表了一次重要的 Vibe Coding: Harness Engineering 範式轉變。
然而,這種範式轉變卻暴露了傳統 Git 工作流的深層瓶頸:
⚠️ Warning: 單一 working directory 的限制
傳統 Git 假設一個儲存庫只有一個工作目錄。但在 AI 輔助開發中,我們需要同時探索多個方案、測試不同實作路徑,單一工作目錄根本無法滿足需求。
分支切換的成本體現在多個層面:
- stash 的痛苦:切換分支前必須 stash 修改,但 AI session 不知道這些檔案被藏起來了
- commit 的壓力:頻繁建立臨時 commit 污染提交歷史
- context 丟失:切換後,AI session 積累的上下文(對話歷史、理解的專案結構)瞬間清空
❗ Important: AI Session 的上下文脆弱性
AI session 不是簡單的命令執行器,它承載著:
- 對話歷史:理解使用者意图的完整鏈條
- 檔案狀態認知:AI「知道」當前檔案的結構、依賴關係
- 思維鏈:多次迭代中積累的推理過程
切換分支會打斷這一切,相當於給 AI「換腦」。
最致命的是:無法並行探索多個方案。在傳統模式中,如果你想嘗試三種不同的架構方案,只能串行:探索方案 A → reset → 探索方案 B → reset → 探索方案 C。這種低效的迭代模式與 AI 快速探索的能力形成鮮明矛盾。
Git Worktree 機制解析
Worktree 是什麼
從技術定義來看,Git Worktree 是一個共享 .git 儲存庫的多 working directory 機制。
📝 Note: 核心概念
- 共享 repository:所有 worktree 共用同一個
.git目錄,共享完整的 commit history、refs、objects- 獨立工作目錄:每個 worktree 有自己的檔案系統目錄,可以獨立 checkout 不同分支
- 分支獨占性:一個 branch 在同一時刻只能在一個 worktree 中被 checkout
與 clone 的區別:
|
|
與 branch 的關係:branch 是抽象的提交鏈,worktree 是具體的檔案系統空間。一個 branch 可以存在於多個 worktree 的歷史中,但只能在一個 worktree 中處於「checked out」狀態。
Worktree 的生命週期
完整流程:
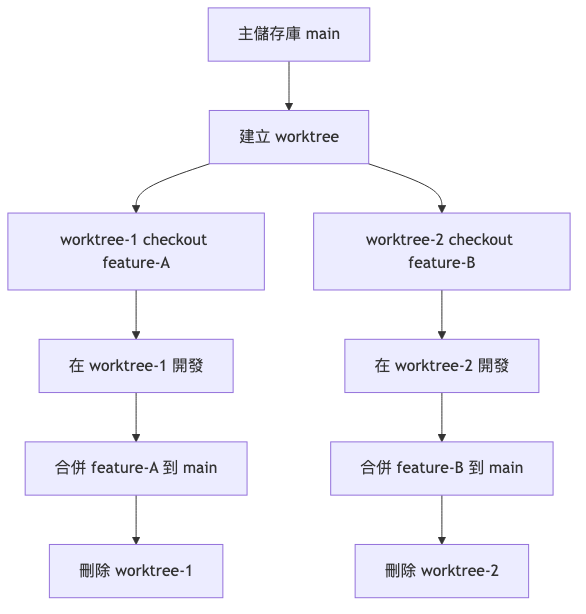
基礎命令
|
|
實用參數組合:
-b <branch>:在建立 worktree 時同時建立新分支--detach:建立游離 HEAD 狀態的 worktree(適合臨時實驗)--lock:鎖定 worktree,防止被 prune 清理
💡 Tip: 推薦實踐
將 worktree 命名與分支名保持一致,例如:
1git worktree add ../project-feature-auth feature-auth
問題深度分析:為什麼 Vibe Coding 需要 Worktree
AI Session 的本質需求
上下文完整性: AI session 不是原子化的命令執行,而是連續的對話流。而在分支切換中保持這種連續性所面臨的挑戰,正是 GSD 如何解決上下文腐化問題 的核心議題。
- 使用者:「幫我重構這個模組」
- AI:「我分析了依賴關係,建議分三步…」
- 使用者:「第二步看起來有問題」
- AI:「你說得對,讓我重新設計…」
這段對話中,AI 積累了:
- 對專案的結構理解
- 對使用者偏好的認知
- 對之前嘗試方案的記憶
切換分支會打斷這個鏈條,AI 需要從零重新建立上下文。
工作環境穩定性: AI 需要穩定的檔案狀態來工作。如果檔案被 stash 或 reset,AI 的「認知地圖」就失效了:
- 「我記得
auth.ts的 API 介面是…」 → 檔案被 stash,AI 找不到它 - 「我們之前修改了…」 → 修改被 reset,AI「記憶」失效
探索自由度: AI 輔助開發的核心優勢是快速迭代探索。但探索需要:
- 實驗性修改不影響 baseline
- 多個方案可以並行存在
- 失敗的嘗試可以隨時丟棄
傳統 Git 的單一工作目錄無法滿足這些需求。
傳統模式的痛點
🔴 Danger: 痛點 1:切換分支 = 丟失 AI 上下文
場景:你在
main分支用 AI 開發 feature-A,突然收到緊急 Bug 修復請求。傳統做法:
- stash 當前修改
- checkout hotfix 分支
- 啟動新的 AI session 處理 bug
- 修復完成,checkout 回 main
- stash pop 恢復修改
- 問題:原 AI session 已丟失,需要重新解釋 feature-A 的設計思路
🔴 Danger: 痛點 2:AI 修改檔案 = stash後 AI 找不到檔案
AI 正在修改
config.ts,你突然需要切換分支。你 stash 修改,切換分支,但 AI 不知道檔案被藏起來了:
- AI:「我繼續修改
config.ts…」- 際:檔案已被 stash,AI 在舊版本上修改 -結果:修改錯亂,stash pop 時產生衝突
🔴 Danger: 痛點 3:探索性修改 = 污染主分支或頻繁 reset
AI嘗試三種架構方案:
- 方案 A:修改 10 個檔案 -發現問題,reset 回起點
- 方案 B:修改 8 個檔案
- 又發現問題,reset
- 方案 C:修改 12 個檔案
結果:主分支被頻繁 reset,commit 歷史混亂,或者不敢 commit導致檔案狀態無法回溯。
🔴 Danger: 痛點 4:無法並行 = 只能串行嘗試不同方案
你想同時讓:
- AI-1 探索前端架構方案
- AI-2 探索後端 API 方案
- AI-3 探索資料庫 schema 方案
傳統模式:只能串行。AI-1 探索 → reset → AI-2 探索 → reset → AI-3 探索
效率損失:3個 AI 本可並行,卻被強制串行,浪費了 AI 的快速迭代能力。
Worktree 如何對症解決
✅ Success: 每個 worktree = 獨立的 AI session 家園
1 2 3 4 5 6 7 8 9# 為 feature-A 建立 worktree,啟動 AI session-1 git worktree add ../project-feature-a feature-a cd ../project-feature-a # AI session-1 在這裡穩定工作 # 為 hotfix 建立 worktree,啟動 AI session-2 git worktree add ../project-hotfix hotfix-123 cd ../project-hotfix # AI session-2 獨立工作,不影響 session-1
✅ Success:無需切換 = 上下文永不丟失
每個 AI session 在自己的 worktree 中:
- 檔案狀態穩定
- 對話歷史連續
- 認知環境一致
不需要 checkout,不需要 stash,不需要打斷 session。
✅ Success: 多 worktree = 多 AI 並行工作
1 2 3 4 5 6 7 8git worktree add ../exploration-a -b exploration-a git worktree add ../exploration-b -b exploration-b git worktree add ../exploration-c -b exploration-c # 在 exploration-a 啟動 AI-1 探索方案 A # 在 exploration-b 啟動 AI-2 探索方案 B # 在 exploration-c 啟動 AI-3 探索方案 C # 三個 AI 同時工作,互不干擾
✅ Success: 實驗隔離 = baseline 始終保持乾淨
主儲存庫(main 分支)始終保持乾淨穩定:
- 作為參考 baseline
- 作為其他 worktree 的 merge 來源
- 不被實驗性修改污染
探索性 worktree 可以隨意實驗:
1 2 3 4# 在 exploration worktree 中大膽嘗試 # 失敗了?直接刪除 worktree git worktree remove ../exploration-failed # 主儲存庫完全不受影響
實戰場景設計
場景 1:多 AI 並行開發
場景描述: 你需要在同一時間開發三個獨立功能:
- Feature-A:使用者認證模組(前端)
- Feature-B:API 效能優化(後端)
- Feature-C:資料庫 schema 重構
傳統困境:只能串行開發,每個功能完成後才能開始下一個。
Worktree 解決方案:
|
|
工作流程:
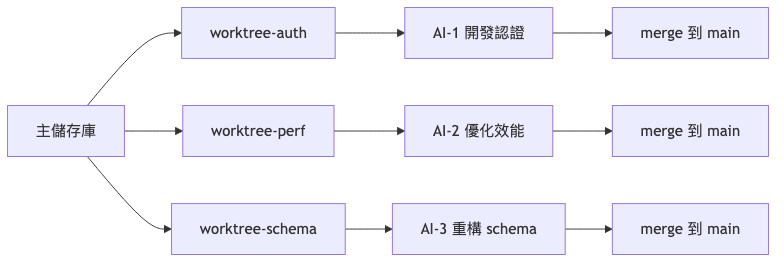
💡 Tip: 最佳實踐
- 每個 worktree 命名清晰,與功能關聯
- 每個 AI session 獨立執行,不要混用
- 定期從 main pull 最新更新,保持同步
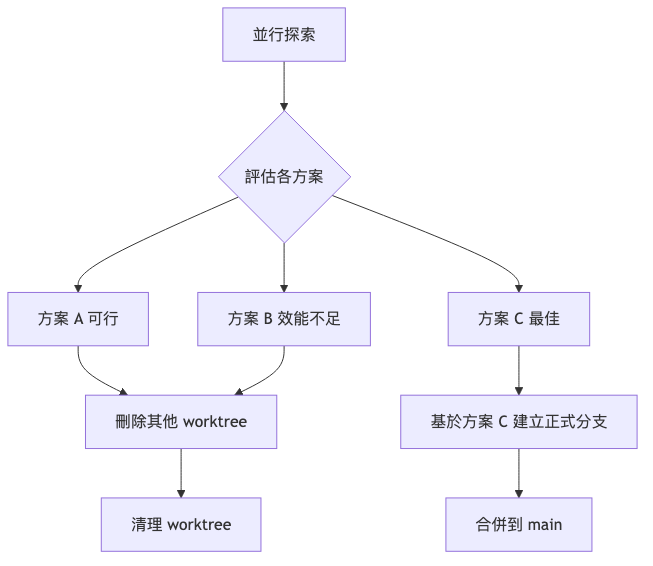
場景 2:實驗性功能探索
場景描述: 你不確定某架構方案是否可行,想快速嘗試多個方向:
- 方案 A:使用 React Server Components
- 方案 B:採用傳統 SPA 架構
- 方案 C:嘗試 Next.js App Router
Worktree 解決方案:
|
|
評估決策流程:
⚠️ Warning: 注意事项
使用
--detach建立游離 HEAD 的 worktree 適合快速實驗:
- 不會建立正式分支
- 可以隨意修改
- 刪除 worktree後不留痕跡
確定方案後,再建立正式分支 worktree 繼續開發。
場景 3:緊急 Bug 修復與主開發並行
場景描述: 你正在用 AI 開發一個大型 feature(已迭代多天),突然收到緊急生產環境 Bug 報告。
傳統困境:
- stash 當前 feature 的所有修改
- checkout hotfix 分支
- 新 AI session 從零開始理解 bug
- hotfix 完成後 checkout 回 feature 分支
- stash pop,衝突處理耗時
- 原 AI session 丟失,需要重新解釋 feature 設計
Worktree 解決方案:
|
|
❗ Important:關鍵優勢
- 零打斷:feature 開發的 AI session 完全不受影響
- 零衝突:兩個 worktree 狨立檔案系統,無需 stash/pop
- 零上下文丟失:每個 AI session 在自己的環境持續工作
場景 4:多方案對比驗證
場景描述: 團隊對某關鍵架構決策存在分歧,需要實際驗證三個方案的效能表現。
Worktree 解決方案:
|
|
決策流程:
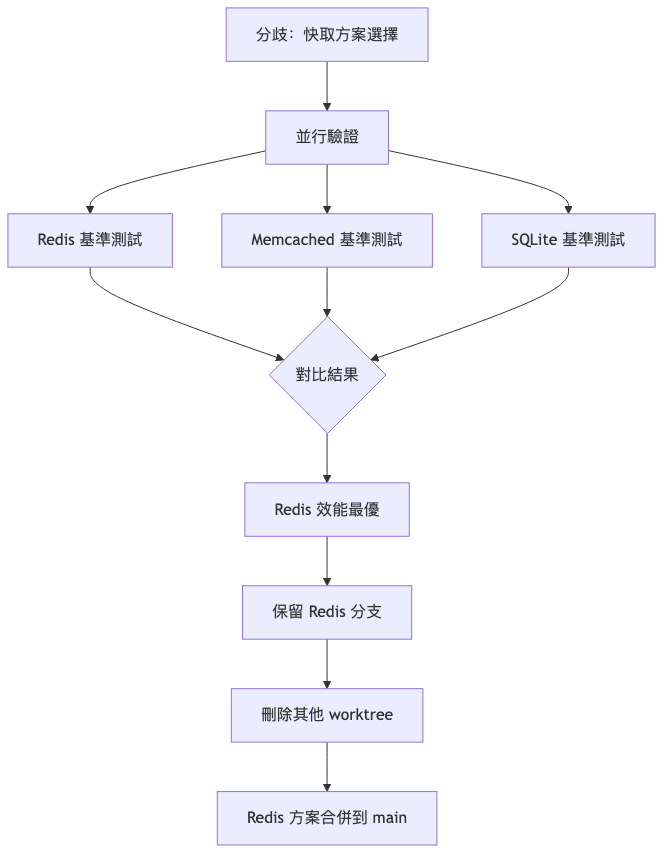
最佳實踐總結
如果你對規格驅動開發感興趣,可以看看我之前的文章:OpenSpec 在 OpenCode 的使用心得。
Worktree 管理規範
💡 Tip: 命名約定
- 功能性 worktree:
project-{feature-name}- 探索性 worktree:
exp-{approach-name}- 修復性 worktree:
project-hotfix-{issue-number}保持命名一致性,便於管理和識別。
💡 Tip: 目錄結構建議
1 2 3 4 5 6~/projects/ ├── main-repo/ # 主儲存庫(保持乾淨) ├── project-feature-a/ # Feature-A worktree ├── project-feature-b/ # Feature-B worktree ├── exp-approach-x/ # 探索性 worktree └── project-hotfix-123/ # Hotfix worktree
AI Session與 Worktree 綁定
❗ Important: 核心原則
一個 AI session = 一個 worktree
不要在同一個 worktree 中混用多個 AI session,也不要讓一個 AI session 跨 worktree 工作。
推薦工具配置:
|
|
清理與維護
定期清理:
|
|
⚠️ Warning: 刪除 worktree前確認
- 對應分支是否已 merge 到 main
- 是否有未提交的重要修改
- 是否有依賴此 worktree 的程式(如正在執行的 AI session)
###與團隊協作的整合
團隊最佳實踐:
|
|
📝 Note: 團隊溝通要點
- Worktree 是本地工具,不共享 -透過 develop 分支同步團隊進度
- 遠端分支對應團隊的 feature,不對應個人的 worktree
结语
對於採用 Vibe Coding 工作流程的團隊來說,擁有一份合適的 AI 模型選擇指南 可以顯著提升開發成果。
Vibe Coding 時代不僅僅是 AI 工具的引入,更是整個開發範式的重構。Git Worktree 不是簡單的技術技巧,而是適配新開發模式的系統性解決方案。
傳統 Git 工作流誕生於「單人連續工作」的時代,而 Vibe Coding 是「多 AI 並行、快速探索、上下文敏感」的新時代。Worktree 恰好彌補了傳統工具與新範式之間的鴻溝。
當你開始使用 Worktree後,你會發現:
- 上下文丟失不再是問題:每個 AI session 有自己的穩定家園
- 並行探索成為常態:多 AI 同時工作,效率倍增
- 實驗不再污染主分支:大膽嘗試,隨時丟棄,主儲存庫始終保持乾淨
這不是 Git 的進階用法,這是 Vibe Coding 的基礎設施。