
引言:重複解釋的煩惱
如果你用過 OpenCode(或者其他 AI 編程助手)一段時間,肯定遇到過這種煩人的情況:每次新對話都得從零開始。你得反覆告訴 AI 你的專案結構、編碼偏好、某個特定的 Linux 配置,甚至是最基本的「我喜歡 TypeScript 而不是 JavaScript」這種事實。
每次會話的前幾分鐘都在重複建立那些早就該被記住的上下文。
這就是我為什麼要嘗試 opencode-mem 這個插件的原因——它能讓 OpenCode 擁有持久化記憶能力。用了幾週之後,我想分享一下使用體驗,以及為什麼我認為它是 AI 輔助開發的利器。
GitHub 倉庫: https://github.com/tickernelz/opencode-mem
核心特性:opencode-mem 的獨特之處
1. 輕量且本地優先
opencode-mem 最吸引我的地方是它的本地優先架構。不同於那些把資料發到外部伺服器的雲端記憶方案,opencode-mem 把所有內容都存在本地:
- SQLite 負責持久化儲存
- USearch 提供快速的向量索引(失敗時自動回退到精確掃描)
- 核心功能零外部 API 依賴
這意味著你的資料除非你主動配置,否則永遠不會離開你的機器。對於注重隱私的人來說,這一點非常重要。
2. 自動學習用戶畫像
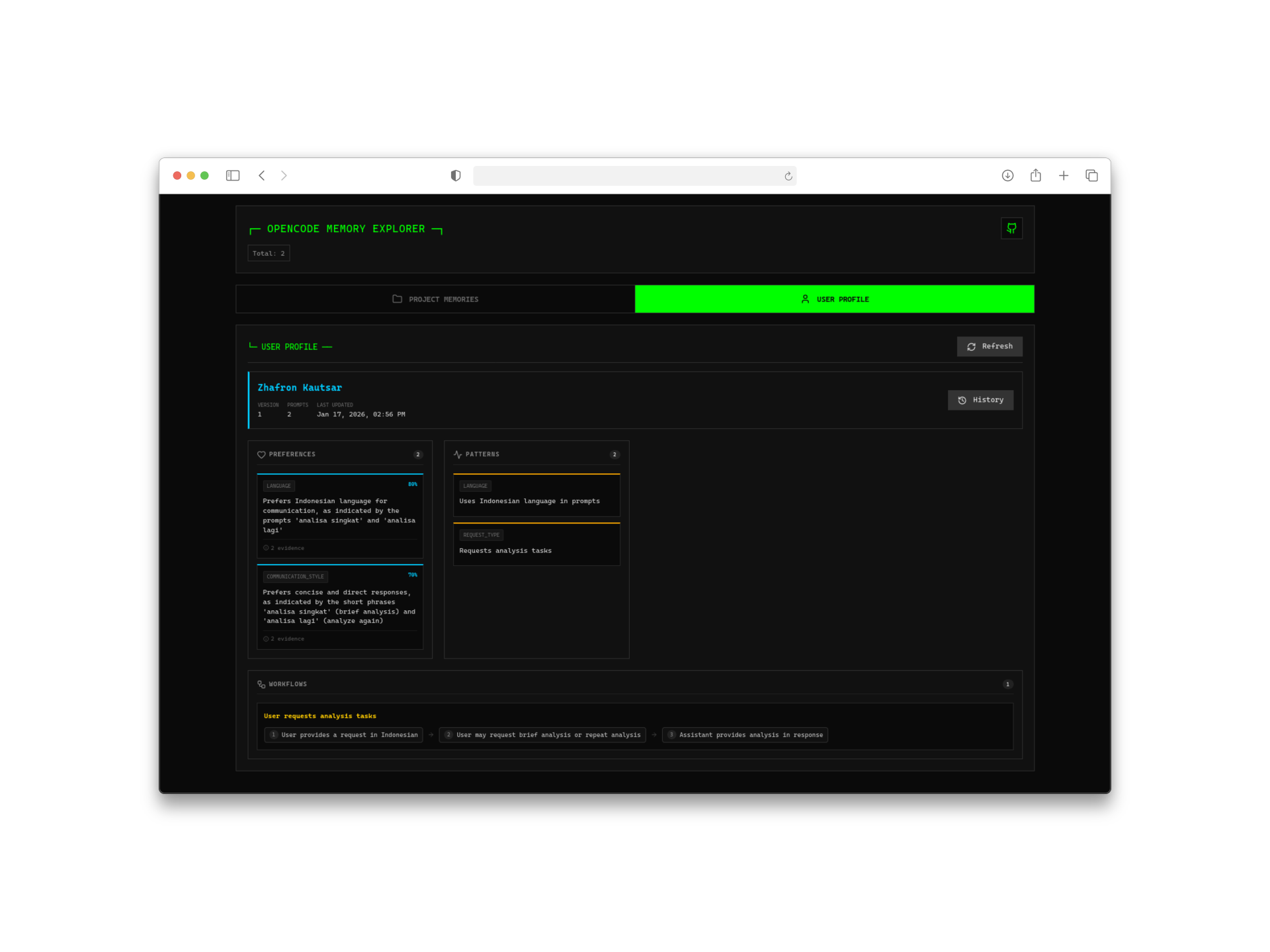
這裡就有意思了。這個插件不只是儲存原始對話記錄——它還會分析你的互動來構建用戶畫像。隨著時間推移,它會學習:
- 你的編碼風格和偏好
- 你常用的技術棧
- 專案中的常見模式
- 個人習慣和快捷鍵
唯一需要呼叫外部 AI 的是在初始畫像生成階段,這時候用 ChatGPT 或相容的模型。之後所有東西都本地運行。
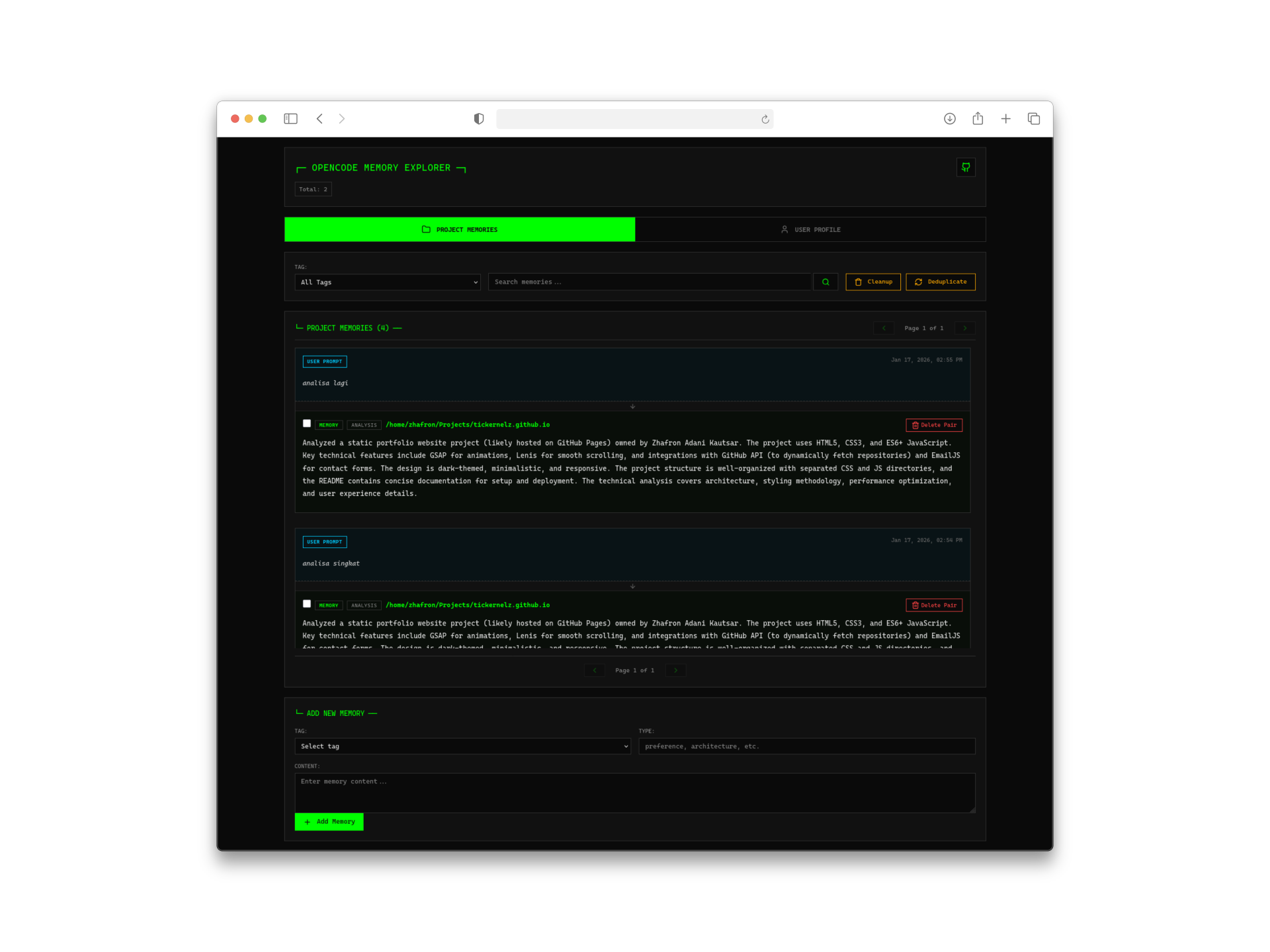
3. Web 管理介面
有時候你想看看 AI 到底記住了你什麼。內建的 Web 介面(訪問地址 http://127.0.0.1:4747)提供了:
- 記憶時間線視覺化
- 用戶畫像查看器
- 記憶搜尋和管理
- 專案專屬記憶瀏覽器
對於一個開發者工具來說,這個介面設計得相當不錯——簡潔、快速、而且真的有用。
工作原理:技術架構解析
了解 opencode-mem 的工作原理後,我更欣賞它的優雅設計了:
自動記憶提取
插件用 AI 自動從對話中提取關鍵資訊。當你提到類似「這個專案用微服務架構」這種重要內容時,它會被捕獲為一條記憶。
智能去重
記憶不是簡單地往資料庫裡一丟了事。系統會合併重複或相似的記憶,保持儲存的整潔和相關性。如果你多次提到同一個偏好,它會整合而不是重複儲存。
雙重儲存策略
- SQLite: 所有持久化資料的源頭
- USearch: 記憶體中的向量索引,提供閃電般的相似度搜尋
如果 USearch 失敗或不可用,系統會優雅地回退到精確向量掃描——不會崩潰,也不會丟資料。
上下文注入
當你開始新會話時,相關的記憶會自動注入 AI 的上下文中。這個過程是透明的——你會注意到 AI「記得」一些不應該從當前會話知道的事情。
安裝與配置
上手非常簡單:
|
|
|
|
就這些。插件會在下次啟動時自動下載。
配置選項
要自定義的話,建立 ~/.config/opencode/opencode-mem.jsonc:
|
|
記憶服務配置
對於 AI 驅動的記憶提取和畫像生成,你需要配置一個大模型提供商:
|
|
我用的是 DeepSeek-V3.2,因為性價比很高——從對話中提取記憶不需要特別大的模型。
實際使用與最佳實踐
基本記憶操作
插件提供了一個 memory 工具供 AI 使用:
|
|
我的踩坑經驗
- 先開啟自動捕獲: 讓系統自然地學習你的模式,不要急於手動干預
- 定期檢查畫像: 每隔幾天看看 Web UI,了解 AI 都學到了你什麼
- 對重要偏好要明說: 雖然自動提取效果不錯,但明確說「記住我喜歡…」能確保捕獲
- 善用記憶類型: 系統會給記憶分類(偏好、學習到的模式、專案配置等),理解這些有助於有效搜尋
與我的工作流整合
我一直把 opencode-mem 和 oh-my-opencode 模型配置 一起使用。兩者配合得很好——持久化記憶加上優化的 agent 模型,真的打造了一個智能編程助手。
如果你也在用 OpenSpec(我在之前的文章裡寫過),記憶在 spec-driven 開發會話之間也是持久存在的。
與替代方案對比
在選定 opencode-mem 之前,我評估了幾個替代品:
| 特性 | opencode-mem | 雲端方案 | 其他本地插件 |
|---|---|---|---|
| 隱私 | 優秀 | 差 | 良好 |
| 成本 | 免費(僅提取用 API) | 訂閱制 | 免費 |
| Web 介面 | 內建 | 不一 | 很少 |
| 用戶畫像學習 | 支援 | 有時支援 | 不支援 |
| 配置複雜度 | 低 | 低 | 中等 |
| 本地嵌入 | 支援 | 不支援 | 有時支援 |
內建的 Web 介面和自動畫像學習是我最終選擇它的決定性因素。
總結
用了 opencode-mem 幾週之後,我已經無法想像回到沒有記憶的編程助手了。不用反覆解釋節省的時間,加上 AI 對我偏好的不斷理解,明顯提升了我的開發效率。
本地優先的方案意味著不用擔心敏感代碼或偏好被發到外部伺服器。Web 介面讓我能看到和控制 AI 知道的內容。而自動學習意味著它會越用越好。
如果你在用 OpenCode 但還沒試過 opencode-mem,我強烈推薦試試。配置簡單,收益立竿見影,而且隱私方面的考量也很重要。
你有沒有嘗試過給 AI 編程工作流添加記憶功能?歡迎在評論區分享你的經驗。