
引言:重复解释的烦恼
如果你用过 OpenCode(或者其他 AI 编程助手)一段时间,肯定遇到过这种烦人的情况:每次新对话都得从零开始。你得反复告诉 AI 你的项目结构、编码偏好、某个特定的 Linux 配置,甚至是最基本的「我喜欢 TypeScript 而不是 JavaScript」这种事实。
每次会话的前几分钟都在重复建立那些早就该被记住的上下文。
这就是我为什么要尝试 opencode-mem 这个插件的原因——它能让 OpenCode 拥有持久化记忆能力。用了几周之后,我想分享一下使用体验,以及为什么我认为它是 AI 辅助开发的利器。
GitHub 仓库: https://github.com/tickernelz/opencode-mem
核心特性:opencode-mem 的独特之处
1. 轻量且本地优先
opencode-mem 最吸引我的地方是它的本地优先架构。不同于那些把数据发到外部服务器的云端记忆方案,opencode-mem 把所有内容都存在本地:
- SQLite 负责持久化存储
- USearch 提供快速的向量索引(失败时自动回退到精确扫描)
- 核心功能零外部 API 依赖
这意味着你的数据除非你主动配置,否则永远不会离开你的机器。对于注重隐私的人来说,这一点非常重要。
2. 自动学习用户画像
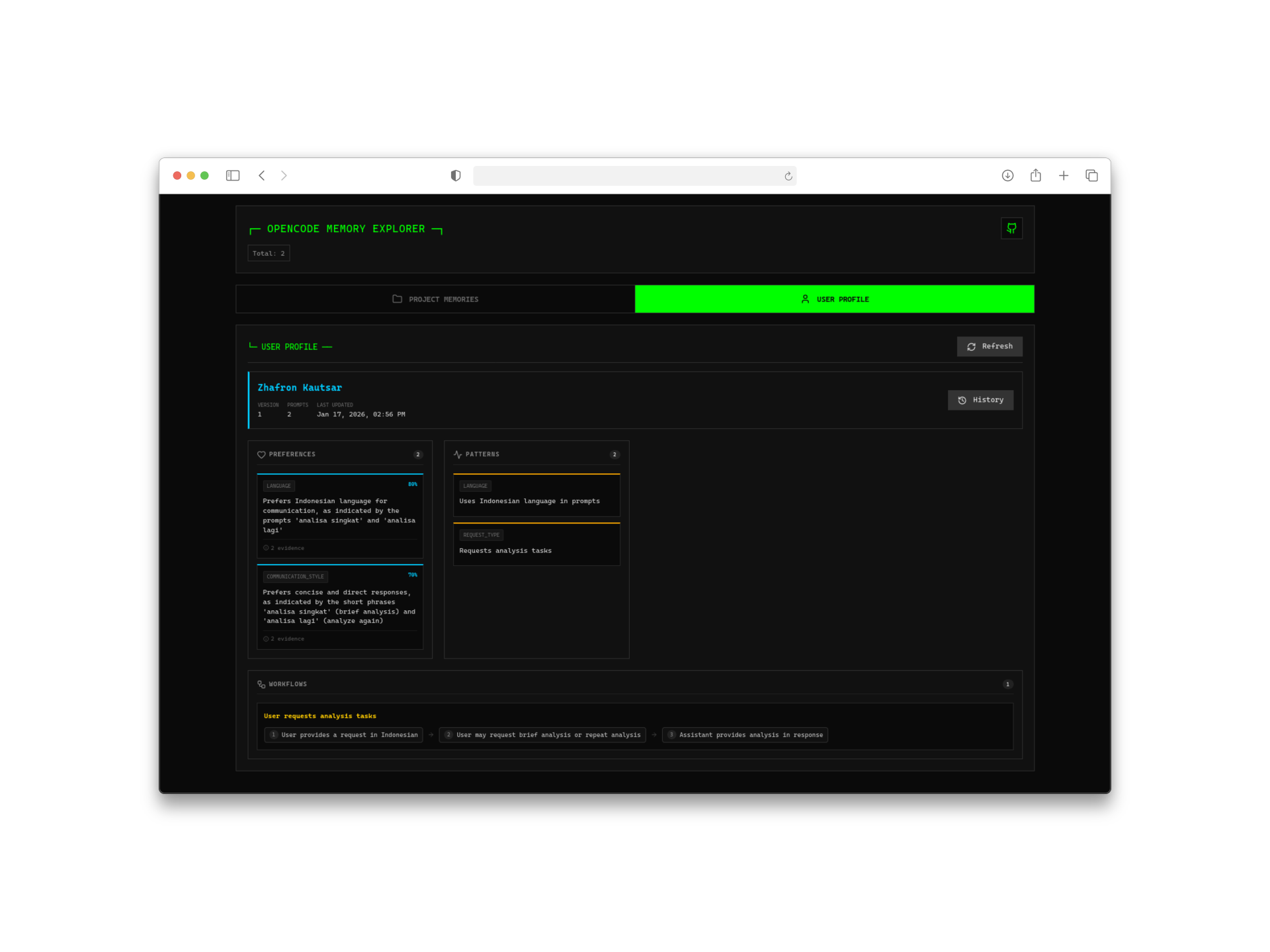
这里就有意思了。这个插件不只是存储原始对话记录——它还会分析你的交互来构建用户画像。随着时间推移,它会学习:
- 你的编码风格和偏好
- 你常用的技术栈
- 项目中的常见模式
- 个人习惯和快捷键
唯一需要调用外部 AI 的是在初始画像生成阶段,这时候用 ChatGPT 或兼容的模型。之后所有东西都本地运行。
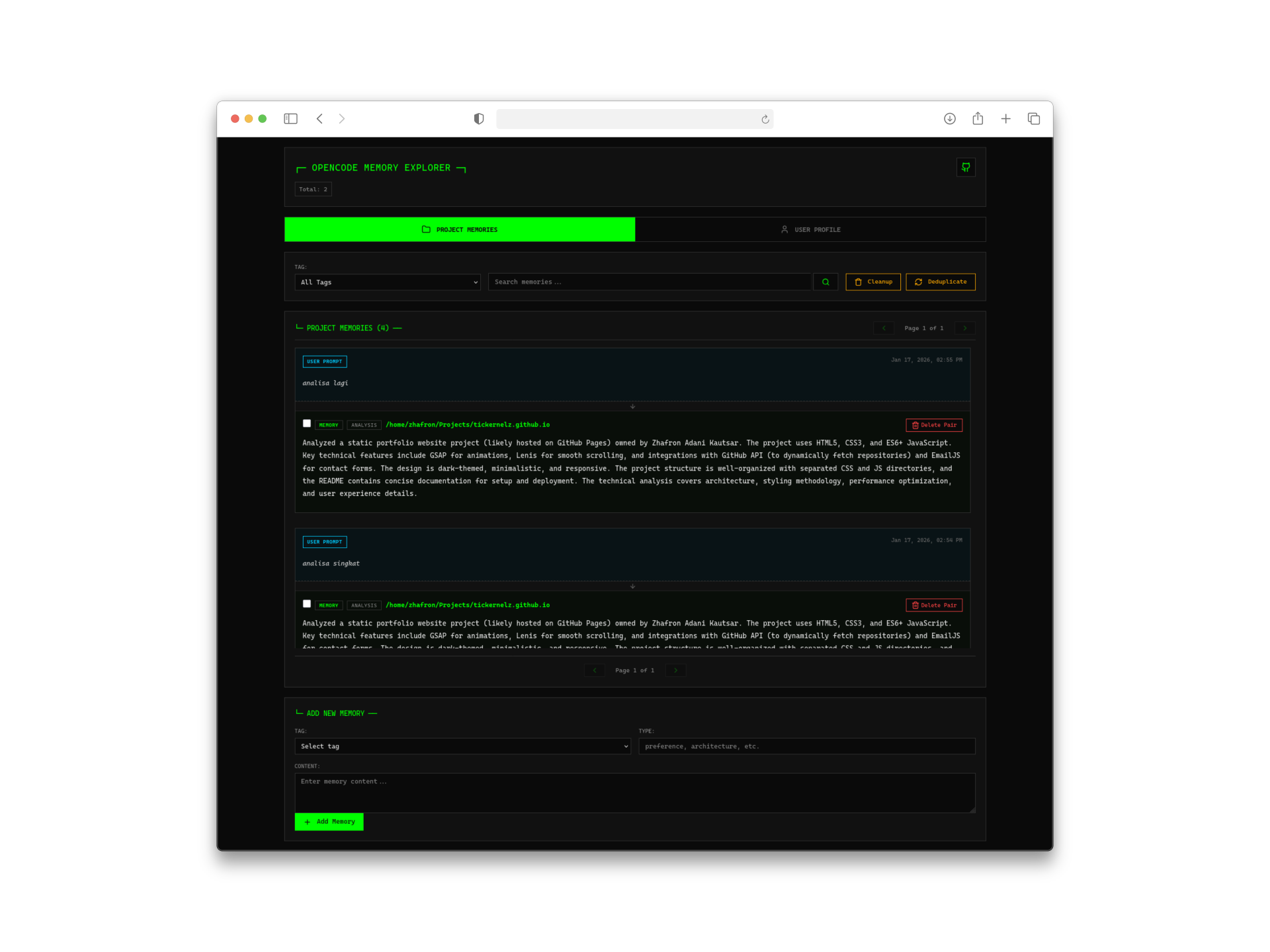
3. Web 管理界面
有时候你想看看 AI 到底记住了你什么。内置的 Web 界面(访问地址 http://127.0.0.1:4747)提供了:
- 记忆时间线可视化
- 用户画像查看器
- 记忆搜索和管理
- 项目专属记忆浏览器
对于一个开发者工具来说,这个界面设计得相当不错——简洁、快速、而且真的有用。
工作原理:技术架构解析
了解 opencode-mem 的工作原理后,我更欣赏它的优雅设计了:
自动记忆提取
插件用 AI 自动从对话中提取关键信息。当你提到类似「这个项目用微服务架构」这种重要内容时,它会被捕获为一条记忆。
智能去重
记忆不是简单地往数据库里一丢了事。系统会合并重复或相似的记忆,保持存储的整洁和相关性。如果你多次提到同一个偏好,它会整合而不是重复存储。
双重存储策略
- SQLite: 所有持久化数据的源头
- USearch: 内存中的向量索引,提供闪电般的相似度搜索
如果 USearch 失败或不可用,系统会优雅地回退到精确向量扫描——不会崩溃,也不会丢数据。
上下文注入
当你开始新会话时,相关的记忆会自动注入 AI 的上下文中。这个过程是透明的——你会注意到 AI「记得」一些不应该从当前会话知道的事情。
安装与配置
上手非常简单:
|
|
|
|
就这些。插件会在下次启动时自动下载。
配置选项
要自定义的话,创建 ~/.config/opencode/opencode-mem.jsonc:
|
|
记忆服务配置
对于 AI 驱动的记忆提取和画像生成,你需要配置一个大模型提供商:
|
|
我用的是 DeepSeek-V3.2,因为性价比很高——从对话中提取记忆不需要特别大的模型。
实际使用与最佳实践
基本记忆操作
插件提供了一个 memory 工具供 AI 使用:
|
|
我的踩坑经验
- 先开启自动捕获: 让系统自然地学习你的模式,不要急于手动干预
- 定期检查画像: 每隔几天看看 Web UI,了解 AI 都学到了你什么
- 对重要偏好要明说: 虽然自动提取效果不错,但明确说「记住我喜欢…」能确保捕获
- 善用记忆类型: 系统会给记忆分类(偏好、学习到的模式、项目配置等),理解这些有助于有效搜索
与我的工作流整合
我一直把 opencode-mem 和 oh-my-opencode 模型配置 一起使用。两者配合得很好——持久化记忆加上优化的 agent 模型,真的打造了一个智能编程助手。
如果你也在用 OpenSpec(我在之前的文章里写过),记忆在 spec-driven 开发会话之间也是持久存在的。
与替代方案对比
在选定 opencode-mem 之前,我评估了几个替代品:
| 特性 | opencode-mem | 云端方案 | 其他本地插件 |
|---|---|---|---|
| 隐私 | 优秀 | 差 | 良好 |
| 成本 | 免费(仅提取用 API) | 订阅制 | 免费 |
| Web 界面 | 内置 | 不一 | 很少 |
| 用户画像学习 | 支持 | 有时支持 | 不支持 |
| 配置复杂度 | 低 | 低 | 中等 |
| 本地嵌入 | 支持 | 不支持 | 有时支持 |
内置的 Web 界面和自动画像学习是我最终选择它的决定性因素。
总结
用了 opencode-mem 几周之后,我已经无法想像回到没有记忆的编程助手了。不用反复解释节省的时间,加上 AI 对我偏好的不断理解,明显提升了我的开发效率。
本地优先的方案意味着不用担心敏感代码或偏好被发到外部服务器。Web 界面让我能看到和控制 AI 知道的内容。而自动学习意味着它会越用越好。
如果你在用 OpenCode 但还没试过 opencode-mem,我强烈推荐试试。配置简单,收益立竿见影,而且隐私方面的考量也很重要。
你有没有尝试过给 AI 编程工作流添加记忆功能?欢迎在评论区分享你的经验。