
はじめに:繰り返し説明する煩わしさ
OpenCode(または他の AI コーディングアシスタント)をしばらく使っていると、こんな煩わしい状況に遭遇したことがあると思います:毎回新しい会話をゼロから始めなければならない。プロジェクト構造、コーディングの好み、特定の Linux 設定、甚至は「TypeScript が JavaScript より好き」という基本的な事実まで、何度も何度も AI に伝えなければなりません。
セッションの最初の数分間は、本来なら覚えておくべきコンテキストを再構築するのに費やされます。
この問題を解決するために私が見つけたのが opencode-mem プラグインです。これにより OpenCode は永続的な記憶能力を得ることができます。数週間使用した後、使用体験を共有し、なぜこれが AI 支援開発のゲームチェンジャーだと思うかを説明したいと思います。
GitHub リポジトリ: https://github.com/tickernelz/opencode-mem
主要機能:opencode-mem の特徴
1. 軽量でローカルファースト
opencode-mem の最も魅力的な点はそのローカルファーストアーキテクチャです。データを外部サーバーに送信するクラウドベースの記憶ソリューションとは異なり、opencode-mem はすべてのコンテンツをローカルに保存します:
- SQLite で永続的なストレージを提供
- USearch で高速なベクトルインデックスを提供(失敗時は自動的に厳密スキャンにフォールバック)
- コア機能に外部 API 依存がゼロ
これは、明示的に設定しない限り、あなたのデータがマシンの外に出ることはないことを意味します。プライバシーを重視する人にとって、これは非常に重要です。
2. 自動ユーザープロファイル学習
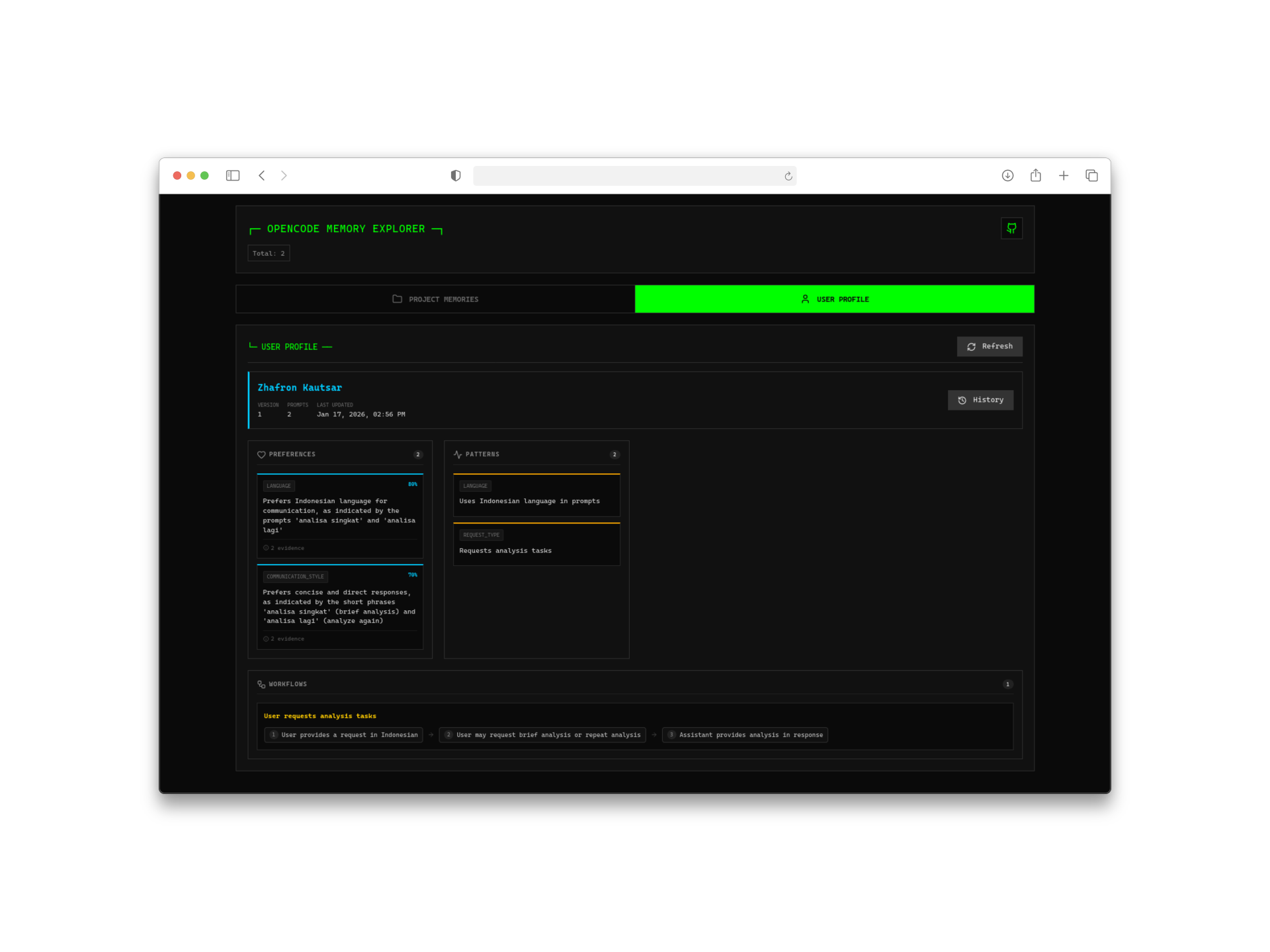
ここが面白いところです。このプラグインは単に生の会話記録を保存するだけでなく、あなたのインタラクションを分析してユーザープロファイルを構築します。時間の経過とともに、以下を学習します:
- あなたのコーディングスタイルと好み
- 頻繁に使用する技術
- プロジェクト内の一般的なパターン
- 個人の規約とショートカット
外部 AI が必要なのは、初期プロファイル生成の段階のみで、ChatGPT または互換性のあるモデルを使用します。その後はすべてローカルで実行されます。
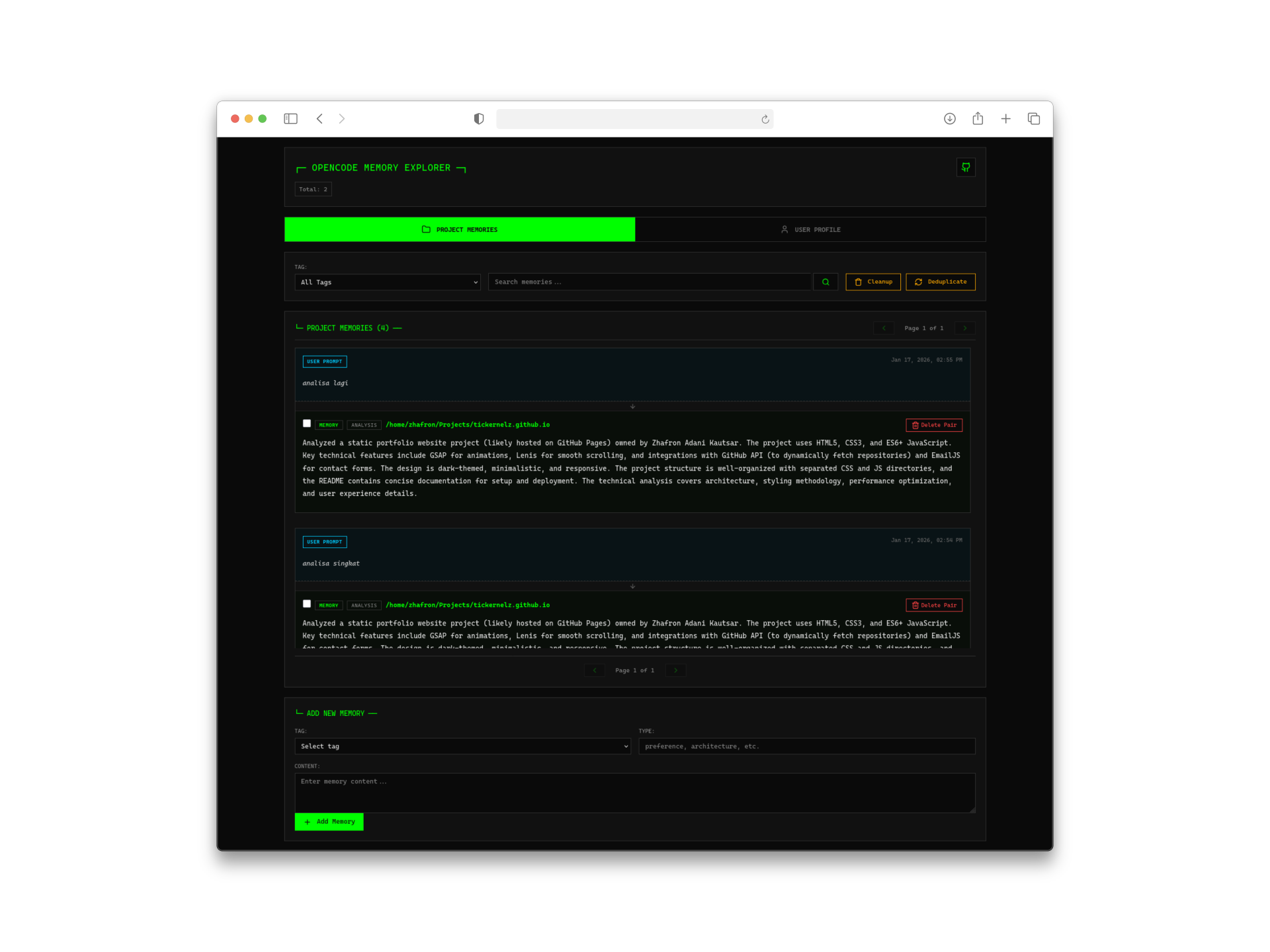
3. Web 管理インターフェース
時々、AI が実際にあなたについて何を覚えているか見たくなることがあります。組み込みの Web インターフェース(http://127.0.0.1:4747 でアクセス可能)は以下を提供します:
- 記憶のタイムライン可視化
- ユーザープロファイルビューア
- 記憶の検索と管理
- プロジェクト固有の記憶ブラウザ
開発者ツールとしては、驚くほどよく設計されています。クリーンで高速、そして実際に役立ちます。
仕組み:技術アーキテクチャの解説
opencode-mem の仕組みを理解すると、そのエレガンスがより一層際立ちます:
自動記憶抽出
プラグインは AI を使用して、会話から重要な情報を自動的に抽出します。「このプロジェクトはマイクロサービスアーキテクチャを使用しています」などの重要な内容に言及すると、それが記憶としてキャプチャされます。
スマートな重複排除
記憶は単にデータベースにダンプされるわけではありません。システムは重複または類似した記憶をマージして、ストレージをクリーンで関連性のあるものに保ちます。同じ好みを複数回言及した場合、重複せずに統合されます。
二重ストレージ戦略
- SQLite: すべての永続データの信頼できる情報源
- USearch: メモリ内のベクトルインデックスで、電光石火の類似性検索を提供
USearch が失敗したり利用できない場合、システムは優雅に厳密なベクトルスキャンにフォールバックします。クラッシュもデータ損失もありません。
コンテキストインジェクション
新しいセッションを開始すると、関連する記憶が自動的に AI のコンテキストに注入されます。このプロセスは透過的です。AI がこのセッションだけでは知るはずのないことを「覚えている」ことに気づくでしょう。
インストールと設定
開始は驚くほどシンプルです:
|
|
|
|
これだけです。プラグインは次回の起動時に自動的にダウンロードされます。
設定オプション
カスタマイズするには、~/.config/opencode/opencode-mem.jsonc を作成します:
|
|
メモリプロバイダー設定
AI 駆動のメモリ抽出とプロファイル生成には、LLM プロバイダーを設定する必要があります:
|
|
私は DeepSeek-V3.2 を使用しています。コストパフォーマンスが高く、会話からメモリを抽出するのに巨大なモデルは必要ないからです。
実際の使用とベストプラクティス
基本的なメモリ操作
プラグインは、AI が使用できる memory ツールを提供します:
|
|
私が学んだベストプラクティス
- 自動キャプチャを有効にして開始: システムに自然にパターンを学習させ、手動での介入は急がない
- プロファイルを定期的に確認: 数日ごとに Web UI を確認し、AI があなたについて何を学習したか把握する
- 重要な好みは明示的に: 自動抽出は優れていますが、「~を覚えておいて」と明示的に言うと確実にキャプチャされる
- メモリタイプを賢く使用: システムはメモリを分類(好み、学習したパターン、プロジェクト設定など)します。これらを理解すると効果的な検索が可能になります
ワークフローとの統合
私は oh-my-opencode モデル設定 と一緒に opencode-mem を使用しています。両者は見事に連携します。永続的なメモリに最適化されたエージェントモデルを加えることで、本当に知的なコーディングアシスタントが完成します。
OpenSpec も使用している場合(以前の記事 で書きました)、spec-driven 開発セッション間でもメモリは永続します。
代替案との比較
opencode-mem を決定する前に、いくつかの代替案を評価しました:
| 機能 | opencode-mem | クラウドソリューション | 他のローカルプラグイン |
|---|---|---|---|
| プライバシー | 優秀 | 劣悪 | 良好 |
| コスト | 無料(抽出のみ API) | サブスクリプション | 無料 |
| Web インターフェース | 組み込み | 様々 | 稀 |
| ユーザープロファイル学習 | あり | 時々あり | なし |
| セットアップの複雑さ | 低 | 低 | 中 |
| ローカル埋め込み | あり | なし | 時々あり |
組み込みの Web インターフェースと自動プロファイル学習が、私が最終的にこれを選んだ決定的な要因でした。
まとめ
opencode-mem を数週間使用した後、メモリのないコーディングアシスタントに戻ることは想像できません。自分自身を繰り返す必要がなくなったことで節約される時間と、AI が私の好みをますます理解するようになったことで、開発ワークフローが明らかに改善されました。
ローカルファーストのアプローチは、機密コードや好みが外部サーバーに送信される心配がないことを意味します。Web インターフェースは、AI が私について知っていることを可視化し制御できます。そして自動学習は、時間とともにますます良くなることを意味します。
OpenCode を使用していて、まだ opencode-mem を試していない場合は、ぜひ試してみてください。セットアップは最小限で、利点は即座に現れ、プライバシーへの配慮も重要です。
AI コーディングワークフローにメモリを追加することを試みたことはありますか?コメントであなたの経験を聞かせてください。